Forums » Программное обеспечение »
Ассемблер. Реализация POPCNT для MC P1
Added by sprin almost 13 years ago
Здравствуйте.
Решил реализовать для MC P1 алгоритм реализации команды POPCNT, которая может быть использована для эффективного поиска в огромном объёме данных.
Она работает посредством подсчета количества бит множества в объекте данных.
Пример приложений, которые получат преимущества от использования этой инструкции: выявление генома, распознавание почерка, медицина и быстрое вычисление хэмминговского расстояния и заполнения.
Ресурсы:
программно-ориентированные ускорители (набор команд)
SSE4 - Википедия
chessprogramming.wikispaces.com собраны основные алгоритмы и ссылки по теме POPCNT.
Benchmarking CRC32 and PopCnt instructions
Алгоритмы реализовал (с учётом возможностей MC P1) по 4 варианта для входных значений размерностью 32 бит и 64 бит.
mc_POPCNT32_v1, mc_POPCNT64_v1 - The PopCount routine
mc_POPCNT32_v2, mc_POPCNT64_v2 - Lookup (Подстановка из таблицы на 256 элементов готовых значений)
mc_POPCNT32_v3, mc_POPCNT64_v3(+b) - Lookup (Подстановка из таблицы на 256 элементов готовых значений)
mc_POPCNT32_v4, mc_POPCNT64_v4 - HAKMEM 169
В теории, если все команды будут выполняться за 1 такт, то можно посчитать минимальное время выполнения функции, что я и сделал:
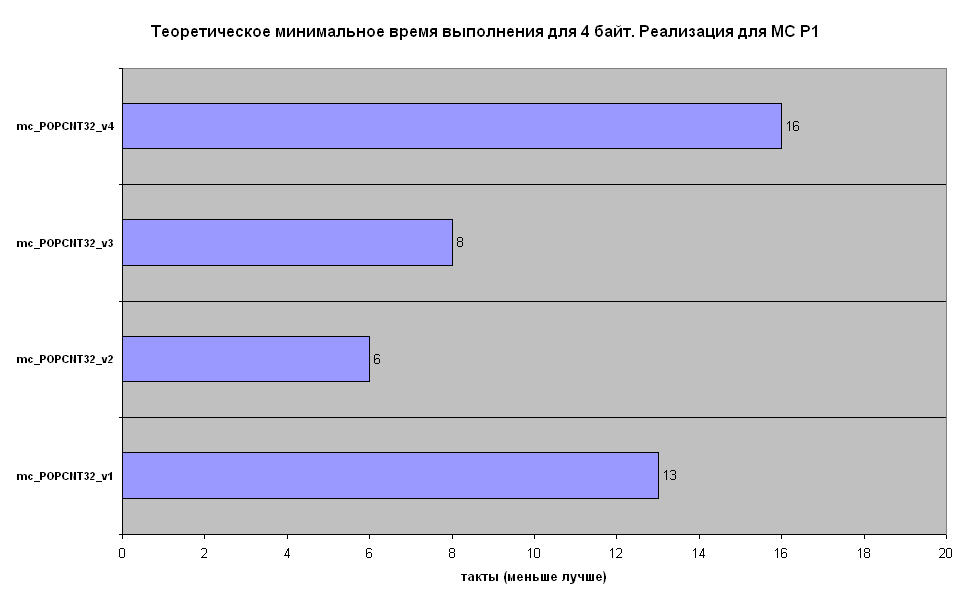
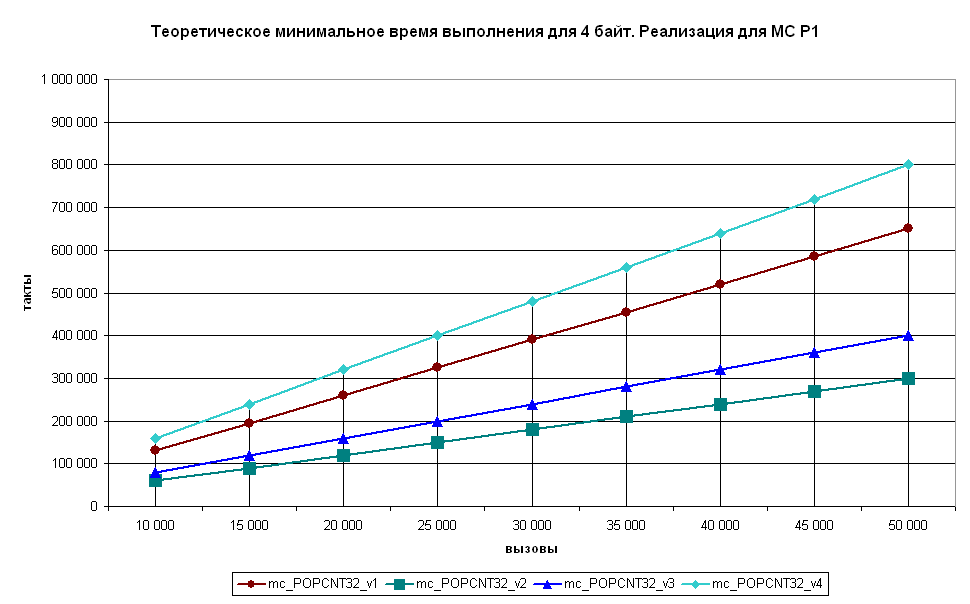
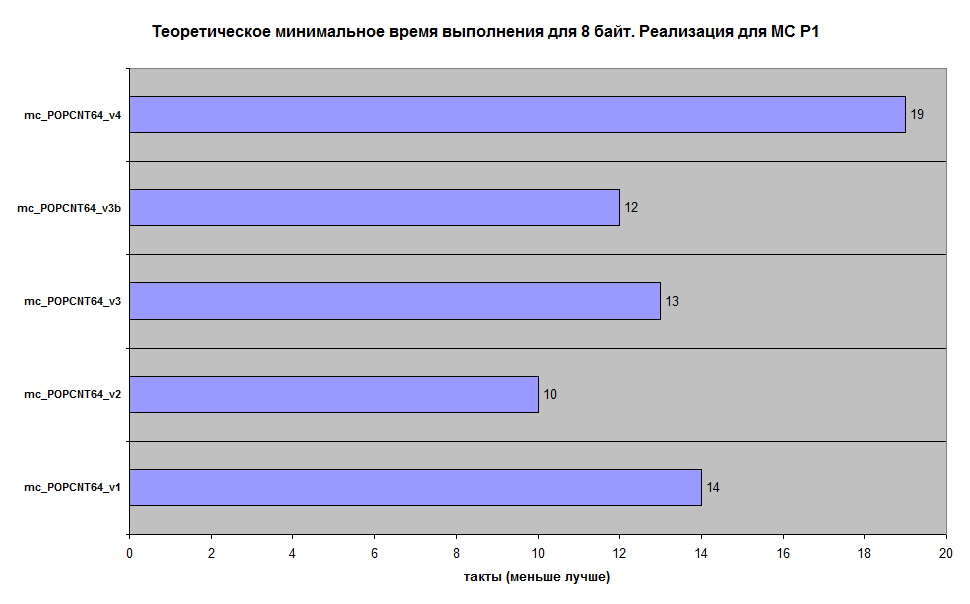
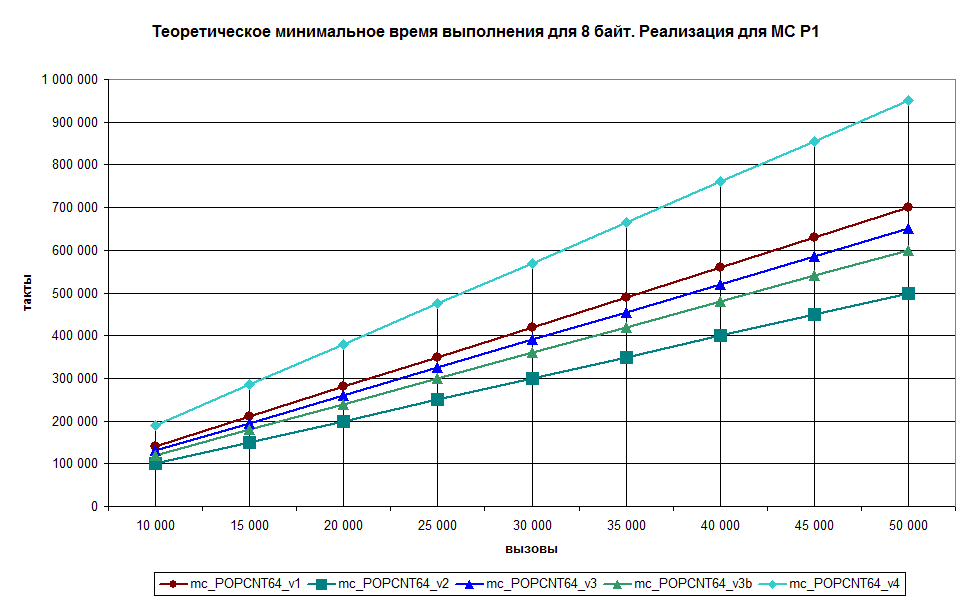
На практике результаты не проверялись.
| mc_POPCNT32.7z (2.01 KB) mc_POPCNT32.7z | |||
| mc_POPCNT64.7z (2.77 KB) mc_POPCNT64.7z | |||
| mc_POPCNT32_01.png (5.8 KB) mc_POPCNT32_01.png | |||
| mc_POPCNT32_02.png (8.27 KB) mc_POPCNT32_02.png | |||
| mc_POPCNT64_01.png (7.08 KB) mc_POPCNT64_01.png | |||
| mc_POPCNT64_02.png (10.9 KB) mc_POPCNT64_02.png |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Replies (51)
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet almost 13 years ago
Спасибо, протестируем и добавим в библиотеку.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by sprin over 12 years ago
Здравствуйте.
Протестировал алгоритмы реализации команды POPCNT на отладочном комплекте НW1-MCp04.
Для тестирования взял простую задачу: "В цикле считается сумма значений возвращаемых алгоритмом".
1. Входные значения из счётчика цикла. (Циклов: 1048576)
2. Входные значения из таблицы в памяти. (размерность исходной таблицы 65536 байт, шаг в массиве 1 байт, считывалось 4 или 8 байт)
Скорость замерял по таймеру "TIM0"
Настройки таймера¶
Show HidePSCPERIOD = 1
time_value_start = 0xFFFFFFFF
TIM_CR(1, 0, 1, 0, 0, TIM0);
Использовался: MultiCletSDK_ru.20131105.exe
Тесты:- 1. Входные значения из счётчика цикла. (Циклов: 1048576)
- Тест 1: Вызов функции. Входные параметры через стек. Результат суммируется с результатом в ПАМЯТИ (читаем из памяти->суммируем->записываем в память)
- Тест 2: Вызов функции. Входные параметры через стек. Результат суммируется с результатом в РОН (читаем из РОН->суммируем->записываем в РОН)
- Тест 3: Вызов функции INLINE. Входной параметр задаётся в РОН. Результат суммируется с результатом в ПАМЯТИ (читаем из памяти->суммируем->записываем в память)
- Тест 4: Вызов функции INLINE. Входной параметр задаётся в РОН. Результат суммируется с результатом в РОН (читаем из РОН->суммируем->записываем в РОН)
- 2. Входные значения из таблицы в памяти. (размерность исходной таблицы 65536 байт, шаг в массиве 1 байт, считывалось 4 или 8 байт)
- Тест 5: Вызов функции. Входные параметры через стек. Результат суммируется с результатом в ПАМЯТИ (читаем из памяти->суммируем->записываем в память)
- Тест 6: Вызов функции. Входные параметры через стек. Результат суммируется с результатом в РОН (читаем из РОН->суммируем->записываем в РОН)
- Тест 7: Вызов функции INLINE. Входной параметр задаётся в ИР (т.е. значение читается из памяти). Результат суммируется с результатом в ПАМЯТИ (читаем из памяти->суммируем->записываем в память)
- Тест 8: Вызов функции INLINE. Входной параметр задаётся в ИР (т.е. значение читается из памяти). Результат суммируется с результатом в РОН (читаем из РОН->суммируем->записываем в РОН)
| НW1-MCp04 | MC P1: | 80 МГц |
| Алгоритм | Тест 1 | Тест 2 | Тест 3 | Тест 4 | Тест 1 | Тест 2 | Тест 3 | Тест 4 | Тест 1 | Тест 2 | Тест 3 | Тест 4 | ||
| Мегабайт/сек * | На 1 цикл уходит тактов (примерно) | Такты (на 1048576 циклов) | ||||||||||||
| mc_POPCNT32_v1 | 2,312 | 2,312 | 132,000 | 132,000 | 138412076 | 138412076 | ||||||||
| mc_POPCNT32_v2 | 3,317 | 3,317 | 92,000 | 92,000 | 96469036 | 96469036 | ||||||||
| mc_POPCNT32_v3 | 2,988 | 2,988 | 8,005 | 4,188 | 102,125 | 102,125 | 38,125 | 72,875 | 107085868 | 107085868 | 39977020 | 76415020 | ||
| mc_POPCNT32_v4 | 1,774 | 1,774 | 172,000 | 172,000 | 180355116 | 180355116 | ||||||||
| mc_POPCNT64_v1 | 4,391 | 4,391 | 139,000 | 139,000 | 145752108 | 145752108 | ||||||||
| mc_POPCNT64_v2 | 5,827 | 5,827 | 104,750 | 104,750 | 109838380 | 109838380 | ||||||||
| mc_POPCNT64_v3 | 5,502 | 5,502 | 13,725 | 7,432 | 110,938 | 110,938 | 44,469 | 82,125 | 116326444 | 116326444 | 46628928 | 86114348 | ||
| mc_POPCNT64_v3b | 5,536 | 5,536 | 110,250 | 110,250 | 115605548 | 115605548 | ||||||||
| mc_POPCNT64_v4 | 3,281 | 3,281 | 186,000 | 186,000 | 195035180 | 195035180 | ||||||||
- 1 Мб = 2^20 байт
Почему "Тест 3" и "Тест 4" дали такие результаты, мне непонятно. Предполагалось, что при использовании РОН ("Тест 4") результат будет не хуже, чем через память("Тест 3").
| Алгоритм | Тест 5 | Тест 6 | Тест 7 | Тест 8 | Тест 5 | Тест 6 | Тест 7 | Тест 8 | Тест 5 | Тест 6 | Тест 7 | Тест 8 | ||
| Мегабайт/сек * | На 1 цикл уходит тактов (примерно) | Такты (на 65536 циклов) | ||||||||||||
| mc_POPCNT32_v1 | 2,295 | 2,295 | 133,001 | 133,001 | 8716334 | 8716334 | ||||||||
| mc_POPCNT32_v2 | 3,281 | 3,281 | 93,001 | 93,001 | 6094894 | 6094894 | ||||||||
| mc_POPCNT32_v3 | 2,961 | 2,961 | 5,606 | 4,100 | 103,062 | 103,062 | 54,439 | 74,439 | 6754302 | 6754302 | 3567720 | 4878440 | ||
| mc_POPCNT32_v4 | 1,764 | 1,764 | 173,001 | 173,001 | 11337774 | 11337774 | ||||||||
| mc_POPCNT64_v1 | 4,360 | 4,360 | 140,001 | 140,001 | 9175086 | 9175086 | ||||||||
| mc_POPCNT64_v2 | 5,769 | 5,769 | 105,797 | 105,797 | 6933494 | 6933494 | ||||||||
| mc_POPCNT64_v3 | 5,457 | 5,457 | 9,458 | 7,220 | 111,846 | 111,846 | 64,534 | 84,534 | 7329934 | 7329934 | 4229290 | 5540010 | ||
| mc_POPCNT64_v3b | 5,486 | 5,486 | 111,250 | 111,250 | 7290904 | 7290904 | ||||||||
| mc_POPCNT64_v4 | 3,264 | 3,264 | 187,001 | 187,001 | 12255278 | 12255278 | ||||||||
- 1 Мб = 2^20 байт
Аналогично, почему "Тест 7" и "Тест 8" дали такие результаты, мне непонятно. Предполагалось, что при использовании РОН ("Тест 8") результат будет не хуже, чем через память("Тест 7").
Кусок кода по INLINE для "Тест 3" и "Тест 4":
Кусок кода по INLINE¶
Show Hide
....
....
....
.data
.align 8
SummPOPCNT: // Сумма POPCNT в памяти
.long \
0
.align 8
popCountOfByte256:
.byte \
0, 1, 1, 2, 1, 2, 2, 3, \
1, 2, 2, 3, 2, 3, 3, 4, \
1, 2, 2, 3, 2, 3, 3, 4, \
2, 3, 3, 4, 3, 4, 4, 5, \
1, 2, 2, 3, 2, 3, 3, 4, \
2, 3, 3, 4, 3, 4, 4, 5, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
1, 2, 2, 3, 2, 3, 3, 4, \
2, 3, 3, 4, 3, 4, 4, 5, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
3, 4, 4, 5, 4, 5, 5, 6, \
4, 5, 5, 6, 5, 6, 6, 7, \
1, 2, 2, 3, 2, 3, 3, 4, \
2, 3, 3, 4, 3, 4, 4, 5, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
3, 4, 4, 5, 4, 5, 5, 6, \
4, 5, 5, 6, 5, 6, 6, 7, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
3, 4, 4, 5, 4, 5, 5, 6, \
4, 5, 5, 6, 5, 6, 6, 7, \
3, 4, 4, 5, 4, 5, 5, 6, \
4, 5, 5, 6, 5, 6, 6, 7, \
4, 5, 5, 6, 5, 6, 6, 7, \
5, 6, 6, 7, 6, 7, 7, 8
.text
//====================================
.alias StartTimer.time_value_start 0x0FFFFFFFF
.alias StartTimer.PSCPERIOD 0x00000001
.alias StartTimer.Iteration_COUNT 1048576
.alias StartTimer.Iteration_STEP 1
....
....
....
//====================================
; Параметры условной компиляции
.alias UseGPR3 1
.alias UseSummPOPCNT 0
//====================================
....
....
....
//====================================
Get_start_time:
rdl TIM0_CNTVAL
setl #gpr1, @1
jmp code_begin
complete
//====================================
code_begin:
; Цикл на StartTimer.Iteration_COUNT шаг StartTimer.Iteration_STEP
r1 := getl StartTimer.Iteration_COUNT
setq #gpr2, @r1
jmp code_loop
complete
//====================================
code_loop:
r1 := getl #gpr2
r2 := subl @r1, StartTimer.Iteration_STEP
r3 := setl #gpr2, @r2
je @r1, Get_finish_time // проверка на конец цикла
jne @r1, code_main
complete
//====================================
// Для 32 бит Inline mc_POPCNT32_v3
code_main:
; Следующий параграф
jmp code_loop
; Считаем количество единиц
a1 := getl #gpr2 //rdl mc_PopCnt32.ARG1
l1 := slrl @a1, 8
l2 := slrl @a1, 16
l3 := slrl @a1, 24
l4 := and @a1, 0xFF
l5 := and @l1, 0xFF
l6 := and @l2, 0xFF
l7 := and @l3, 0xFF
l8 := addl @l4, popCountOfByte256
l9 := addl @l5, popCountOfByte256
l10 := addl @l6, popCountOfByte256
l11 := addl @l7, popCountOfByte256
l12 := rdb @l8
l13 := rdb @l9
l14 := rdb @l10
l15 := rdb @l11
l16 := addl @l12, @l13
l17 := addl @l14, @l15
l18 := addl @l16, @l17
.ifne UseGPR3 // Сохраняем в регистре
r2 := getl #gpr3
r4 := addl @r2, @l18
; Результат
setl #gpr3, @r4
.endif
.ifne UseSummPOPCNT // Сохраняем в память
r2 := rdl SummPOPCNT
r4 := addl @r2, @l18
; Результат
wrl @r4, SummPOPCNT
.endif
complete
//====================================
Get_finish_time:
r1 := rdl TIM0_CNTVAL
r2 := getl #gpr1
r3 := subl @r2, @r1
r4 := slll @r3, 0x1
wrl @r4, #ir1 ; записываем новый результат
getl 0x0
wrl @1, TIM0_CR ; останавливаем таймер
jmp StartTimer.return
complete
//====================================
StartTimer.return:
....
....
....
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by Zveruga over 12 years ago
А можно таблицу результатов тестирования суммирования битов в блоках размером 250 и 65537 байт с указанием количества потребовавшихся тактов, чтобы сравнить с тестами Петра Канковского (если я правильно понял фамилию Peter Kankowski)?
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
А где в 4-м тесте используются РОНы? Что-то я не заметил их. Или прикреплённые выше исходники - это не последняя версия?
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by sprin over 12 years ago
Zveruga wrote:
А можно таблицу результатов тестирования суммирования битов в блоках размером 250 и 65537 байт с указанием количества потребовавшихся тактов, чтобы сравнить с тестами Петра Канковского (если я правильно понял фамилию Peter Kankowski)?
Добавил в пост выше тестирование через таблицу размерностью 65536, шаг в массиве 1 байт, считывалось 4 или 8 байт. Это немного не то что надо, но оценить можно.
krufter_multiclet wrote:
А где в 4-м тесте используются РОНы? Что-то я не заметил их. Или прикреплённые выше исходники - это не последняя версия?
Добавил в пост выше кусок кода INLINE как пример реализации. Суммировать в РОН или ПАМЯТЬ задаётся в "параметрах условной компиляции", если не 0, то блок будет компилироваться, одновременно оба параметра не могут быть 0 или не 0:
; Параметры условной компиляции
.alias UseGPR3 1
.alias UseSummPOPCNT 0
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by Zveruga over 12 years ago
В одном цикле подсчитывается количество битов равных "1" в одном байте? Если так, то это на порядок хуже чем в процессорах архитектуры х86. Минимум 54 такта на подсчет количества битов в одном байте это слишком много. Даже если перебирать все биты поочерёдно, коих всего 8 штук, должно выйти быстрее. Где-то, что-то не так.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by sprin over 12 years ago
Zveruga wrote:
В одном цикле подсчитывается количество битов равных "1" в одном байте? Если так, то это на порядок хуже чем в процессорах архитектуры х86.
Нет, в зависимости от реализации алгоритма или в 4 (POPCNT_32) или в 8 (POPCNT_64) байтах.
Пост выше по таблице уточнил.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by Zveruga over 12 years ago
Если в цикле х32 подсчитывается количество битов в 4-х байтах, то во время теста в 65536 циклов будет вычислено 262144 байта.
Как я понял вы применили алгоритм bit hacks, когда есть специальная таблица из 256 байтов и рассчитываемый байт является индексом для поиска в этой таблице готового результата. Как в таком алгоритме обойтись без памяти не знаю.
Согласно тестам Петра Канковского на других процессорах без применения специальных инструкций используя метод bit hacks для вычисления 262151 байтов затрачивается 507126 тактов.
Мультиклет затрачивает на таблицу из 262144 байта минимум 3567720 тактов, это в 7 раз хуже.
В общем нужно разбирать текущий алгоритм и искать алгоритмы расчета без использования памяти.
Возможно причина кроется в индексном обращении к памяти. Эта команда выполняется не за один такт.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
1) Можно попробовать отключить контроль чтения и записи, бит 6 в PSW.
2) Обращение к памяти конечно может что-то задержать, но не так сильно.
3) В идеале нам нужно эту программу проанализировать и посмотреть где и что нас задерживает.
4) Измеряли сколько тактов длится параграф code_main?
5) Если анализировать большее количество данных в одном параграфе, то скорость будет подниматься в разы.
6) code_loop можно же перенести в параграф code_main, этим мы сократим время.
7) Сэкономить такты мы также можем применением в качестве счётчика индексных регистров.
На мой взгляд получить ускорение в 7 раз реально, но надо постараться сделать быстрее чем у x86.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by sprin over 12 years ago
Я тут ещё немного поэкспериментировал, получилось:
1. Сделал цикл + расчёт в одном параграфе, результат остался примерно прежним (по сравнению с "Тест 7" mc_POPCNT64_v3 разница в тактах равна 22580, т.е. менее 0,6%)
2. 6 бит регистра PSW на результаты не повлиял на пункт 1 (остальные варианты не тестировал)
3. Решил ради интереса убрать запись РЕЗУЛЬТАТА в ПАМЯТЬ/РОН ("wrl @r4, SummPOPCNT"/"setl #gpr3, @r4" см. "Кусок кода по INLINE") на "Тест 7" mc_POPCNT64_v3 получилось:
| Алгоритм | Мегабайт/сек | На 1 цикл уходит тактов (примерно) | Такты (на 65536 циклов) |
| mc_POPCNT64_v3 | 16,599 | 36,771 | 2409854 |
т.е. получается ... одним словом плохо у МС P1 с записью. Тратить примерно 27 тактов на запись, это как-то многовато. Хотя может у МС умный планировщик, и некоторые команды он выбрасывает, тогда на запись получится меньше 27 тактов?
И ещё похоже, что между параграфами проходит примерно от 10 тактов.
4. Индексные регистры конечно можно использовать в качестве автоматического счётчика, но ограничение в 65536 итераций сильно усложняет их использование.
| Test_POPCNT.7z (84 KB) Test_POPCNT.7z |
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
Советы по ускорению я конечно дать могу, но сначала мы посмотрим временные диаграммы, как и что работает на вашей программе.
Тут не в записи дело, c записью плохо быть не должно, просто дело в том, что когда стоит запись в конце клетки не пойдут выбирать команды из следующего параграфа, но 27 тактов многовато, нам нужно у себя перепроверить сначала. Спасибо за подробные тесты и эксперименты, как проанализируем результат работы программы, так сразу отпишусь.
Так ради эксперимента попробуйте поставить getl 123 после последней команды в параграфе.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by sprin over 12 years ago
krufter_multiclet wrote:
Так ради эксперимента попробуйте поставить getl 123 после последней команды в параграфе.
Пробовал, ставить в конец параграфа "code_main" 3 команды "getl 0". На результат не повлияло.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
С первым процессором пока разбираемся, на новом процессоре P2 код во вложении отработал в несколько раз быстрее.
Вложение
Пример для теста¶
Show Hide;Constant list
.include "constant_asm_V2.inc"
.data
.align 8
SummPOPCNT: // Сумма POPCNT в памяти
.long \
0.align 8popCountOfByte256:
.byte \
0, 1, 1, 2, 1, 2, 2, 3, \
1, 2, 2, 3, 2, 3, 3, 4, \
1, 2, 2, 3, 2, 3, 3, 4, \
2, 3, 3, 4, 3, 4, 4, 5, \
1, 2, 2, 3, 2, 3, 3, 4, \
2, 3, 3, 4, 3, 4, 4, 5, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
1, 2, 2, 3, 2, 3, 3, 4, \
2, 3, 3, 4, 3, 4, 4, 5, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
3, 4, 4, 5, 4, 5, 5, 6, \
4, 5, 5, 6, 5, 6, 6, 7, \
1, 2, 2, 3, 2, 3, 3, 4, \
2, 3, 3, 4, 3, 4, 4, 5, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
3, 4, 4, 5, 4, 5, 5, 6, \
4, 5, 5, 6, 5, 6, 6, 7, \
2, 3, 3, 4, 3, 4, 4, 5, \
3, 4, 4, 5, 4, 5, 5, 6, \
3, 4, 4, 5, 4, 5, 5, 6, \
4, 5, 5, 6, 5, 6, 6, 7, \
3, 4, 4, 5, 4, 5, 5, 6, \
4, 5, 5, 6, 5, 6, 6, 7, \
4, 5, 5, 6, 5, 6, 6, 7, \
5, 6, 6, 7, 6, 7, 7, 8.text
//====================================
.alias StartTimer.time_value_start 0x0FFFFFFFF
.alias StartTimer.PSCPERIOD 0x00000001
.alias StartTimer.Iteration_COUNT 1
.alias StartTimer.Iteration_STEP 1
//====================================
; Параметры условной компиляции
.alias UseGPR3 1
.alias UseSummPOPCNT 0
//====================================//====================================
start:
getl 0xFFFFFFFF
wrl @1, TIM0_CNT ;период
getl 0x00000001
wrl @1, TIM0_PSCPER ;значение предделителя
jmp timer_start
complete
timer_start:
getl 0x00000005
wrl @1, TIM0_CR
jmp Get_start_time
complete
Get_start_time:
rdl TIM0_CNTVAL
setl #1, @1jmp code_begincomplete
//====================================
code_begin:
; Цикл на StartTimer.Iteration_COUNT шаг StartTimer.Iteration_STEP
r1 := getl StartTimer.Iteration_COUNT
setq #2, @r1jmp code_loopcomplete
//====================================
code_loop:
r1 := getl #2
r2 := subl @r1, StartTimer.Iteration_STEP
r3 := setl #2, @r2je @r1, Get_finish_time // проверка на конец цикла
jne @r1, code_maincomplete
//====================================
// Для 32 бит Inline mc_POPCNT32_v3
code_main:
; Следующий параграф
jmp code_loop; Считаем количество единиц
a1 := getl #2 //rdl mc_PopCnt32.ARG1l1 := slrl @a1, 8
l2 := slrl @a1, 16
l3 := slrl @a1, 24l4 := and @a1, 0xFFl5 := and @l1, 0xFF
l6 := and @l2, 0xFF
l7 := and @l3, 0xFFl8 := addl @l4, popCountOfByte256
l9 := addl @l5, popCountOfByte256
l10 := addl @l6, popCountOfByte256
l11 := addl @l7, popCountOfByte256l12 := rdb @l8
l13 := rdb @l9
l14 := rdb @l10
l15 := rdb @l11l16 := addl @l12, @l13
l17 := addl @l14, @l15l18 := addl @l16, @l17// Сохраняем в регистре
r2 := getl #3
r4 := addl @r2, @l18
; Результат
setl #3, @r4; .ifne UseSummPOPCNT // Сохраняем в память
; r2 := rdl SummPOPCNT
; r4 := addl @r2, @l18
; ; Результат
; ; wrl @r4, SummPOPCNT
; .endifcomplete
//====================================
Get_finish_time:
r1 := rdl TIM0_CNTVAL
r2 := getl #1
r3 := subl @r2, @r1
r4 := slll @r3, 0x1setl #3, @r4 ; записываем новый результатgetl 0x0
wrl @1, TIM0_CR ; останавливаем таймер
jmp endcomplete
//====================================
end:
getl #3
wrl @1, 0x40000
jmp full_end
complete
full_end:
getl 123
complete
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
sprin, а можете файл выложить с ответами, т.е. то что должно лежать в памяти после 65536 циклов.
У процессоров нет умного планировщика, т.е. команды не отбрасываются, если они есть в буфере, то они выполнятся.
И ещё вопрос если, например, процессор сделает за 30 тактов один цикл из тех трёх параграфов, что я привёл в посте выше, то это нормально или нет?
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by sprin over 12 years ago
Здравствуйте.
krufter_multiclet wrote:
sprin, а можете файл выложить с ответами, т.е. то что должно лежать в памяти после 65536 циклов.
У процессоров нет умного планировщика, т.е. команды не отбрасываются, если они есть в буфере, то они выполнятся.
И ещё вопрос если, например, процессор сделает за 30 тактов один цикл из тех трёх параграфов, что я привёл в посте выше, то это нормально или нет?
1. Как я понимаю, вы используете "Тест 4", только на другое количество тактов. Тут есть один нюанс, если вы используете код, что привели выше, то надо дополнительно сначала обнулять регистр суммы. А итоговую сумму для такого цикла как в примере, можно вычислить по формуле: POPCNT(SUM(1 .. 2 N)) = (2 N) / 2 * N, где N >= 1. Т.е. (2 16) / 2 * 16 = 524288, для (2 20) / 2 * 20 = 10485760. Если не ошибся, то вроде так. Было бы неплохо протестировать и на массиве ("Тест 7" и "Тест 8" исходник давал выше )
2. Понятно
3. Тут вопрос не ко мне, но если сравнивать с Intel, то это примерно раз в 5 медленнее. (На самом деле сравнивать с Intel не считаю разумным, лучше сравнивать в своей весовой категории, было бы неплохо сравнить с Raspberry PI). Если количество сделанных циклов достаточно большое, то влияние параграфов на считывание время начала и окончания расчётов будут минимальны, и получится будут влиять только 2 параграфа (в примере выше: цикл, тело). Так что лучше брать достаточно большое количество циклов. Дальше просто считаем сколько тактов ушло на 1 цикл.
Кстати можно ещё протестировать на P2 двумя параграфами (цикл, тело) и одним параграфом (цикл + тело) и посмотреть сколько уходит тактов между параграфами и есть ли разница (на P1 её почти не было).
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by Zveruga over 12 years ago
Тут без специальной команды ни как. Любое условие, а в алгоритме popcnt их много, замедляет работу Мультиклета. Значит нужно применить такой алгоритм, в котором в пределах одного параграфа производится максимум вычислений без каких-либо сравнений (выполнения перехода между параграфами). По моему простым побитовым сдвигом байта для подсчета битов используя команды slr и adc (сложение с учетом переноса) можно посчитать быстрее, но у Мультиклета 4 клетки и сдвиг байта в каждой клетке будет выдавать результат во флаг переноса. Реализовать такой алгоритм оптимально будет невозможно. Тут поможет только ввод специальной команды, коих в Мультиклете так мало.
Можно также реализовать такой алгоритм как обработка каждого байта 8 раз через команду and выделяющую бит, а потом сдвигая результат до первого разряда. Далее нужно просто сложить все 8 результатов. Но такой алгоритм тоже займет много тактов, но исключит все промежуточные условные переходы.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
В новом процессоре команд добавится прилично. Но мне пока запрещено выкладывать систему команд в открытый доступ.
Значит нужно применить такой алгоритм, в котором в пределах одного параграфа производится максимум вычислений
Чем больше вычислений производится в одном параграфе, тем лучше. Сравнивать с Intel необходимо, только нужно определиться с каким именно и посмотреть результат работы.
Протестирую время работы при большом цикле, а также посмотрю разницу между двумя параграфами (цикл, тело) и одним параграфом (цикл + тело). Но для начала нужно разобраться откуда такие задержки в P1.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
sprin wrote:
3. Тут вопрос не ко мне, но если сравнивать с Intel, то это примерно раз в 5 медленнее. (На самом деле сравнивать с Intel не считаю разумным, лучше сравнивать в своей весовой категории, было бы неплохо сравнить с Raspberry PI). Если количество сделанных циклов достаточно большое, то влияние параграфов на считывание время начала и окончания расчётов будут минимальны, и получится будут влиять только 2 параграфа (в примере выше: цикл, тело). Так что лучше брать достаточно большое количество циклов. Дальше просто считаем сколько тактов ушло на 1 цикл.
Кстати можно ещё протестировать на P2 двумя параграфами (цикл, тело) и одним параграфом (цикл + тело) и посмотреть сколько уходит тактов между параграфами и есть ли разница (на P1 её почти не было).
Т.е. если у нас те 3 параграфа идут за 30 тактов, то Интел сделает за 6 тактов? А можно ссылку на результаты Интела.
Просто 6 тактов никак не выжать и на другом процессоре.
P.S. Завтра проверю тест на новом процессоре, посмотрим отличия.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by sprin over 12 years ago
krufter_multiclet wrote:
Т.е. если у нас те 3 параграфа идут за 30 тактов, то Интел сделает за 6 тактов? А можно ссылку на результаты Интела.
Просто 6 тактов никак не выжать и на другом процессоре.
Первый пост 4 ссылка - "Benchmarking CRC32 and PopCnt instructions".
Там смотрим в "PopCnt instruction" табличку. Строка с тестом "Table" и размерностью "262151 byte" (т.к. там входные данные по 4 байта, а нам надо для 65536 циклов). Получаем примерно 6,347 тактов за 1 цикл. Тут ничего особого нет, т.к. на Intel часть команд декодируются и выполняются параллельно.
Есть ещё одна особенность, та реализация теста "Table" не совсем хорошо сделана, если взять второй вариант , то получится ещё быстрее.
Вот пример на довольно стареньком процессоре:
Intel(R) Celeron(R) D CPU 3.06GHz¶
Show Hide
Processor 1 ID = 0
Number of cores 1 (max 1)
Number of threads 1 (max 1)
Name Intel Celeron 347
Codename Cedar Mill
Specification Intel(R) Celeron(R) D CPU 3.06GHz
Package (platform ID) Socket 775 LGA (0x2)
CPUID F.6.5
Extended CPUID F.6
Core Stepping D0
Technology 65 nm
Core Speed 3066.7 MHz
Multiplier x FSB 23.0 x 133.3 MHz
Rated Bus speed 533.3 MHz
Stock frequency 3066 MHz
Instructions sets MMX, SSE, SSE2, SSE3, EM64T
L1 Data cache 16 KBytes, 8-way set associative, 64-byte line size
Trace cache 12 Kuops, 8-way set associative
L2 cache 512 KBytes, 8-way set associative, 64-byte line size
FID/VID Control no
Результат¶
Show Hide
250 1025 4103 16384 65537 262151 1048576
Dilip Sarwate 2254 [f0c40ca9] 7682 [7b30d248] 29210 [f2a67bc2] 115782 [ab540a8f] 460759 [1e3904dc] 1844071 [500bdca5] 7478680 [8b91984d]
Richard Black 2300 [f0c40ca9] 7912 [7b30d248] 30222 [f2a67bc2] 119301 [ab540a8f] 475617 [1e3904dc] 1902928 [500bdca5] 7726252 [8b91984d]
Slicing-by-4 1426 [f0c40ca9] 4117 [7b30d248] 14904 [f2a67bc2] 59363 [ab540a8f] 232415 [1e3904dc] 929085 [500bdca5] 3830075 [8b91984d]
Slicing-by-8 1150 [f0c40ca9] 2944 [7b30d248] 10373 [f2a67bc2] 40388 [ab540a8f] 156791 [1e3904dc] 629740 [500bdca5] 2621057 [8b91984d]
CRC32 instruction is not supported on this processor
250 1025 4103 16384 65537 262151 1048576
Bit Hacks 1357 [ 3d5] 3887 [ 100a] 13869 [ 4012] 56718 [ ff15] 224641 [ 3fc82] 899576 [ ffe8a] 3693248 [ 40032a]
Table 1288 [ 3d5] 3726 [ 100a] 13409 [ 4012] 54257 [ ff15] 245778 [ 3fc82] 999028 [ ffe8a] 4055268 [ 40032a]
Table2 1058 [ 3d5] 2668 [ 100a] 9016 [ 4012] 38019 [ ff15] 165623 [ 3fc82] 657225 [ ffe8a] 2627727 [ 40032a]
BK's way 6486 [ 3d5] 26266 [ 100a] 104098 [ 4012] 412528 [ ff15] 1340716 [ 3fc82] 5387290 [ ffe8a]21682491 [ 40032a]
HAKMEM 169 1794 [ 3d5] 5681 [ 100a] 21068 [ 4012] 82501 [ ff15] 328348 [ 3fc82] 1315117 [ ffe8a] 5355642 [ 40032a]
SSE2 1081 [ 3d5] 2254 [ 100a] 6417 [ 4012] 23322 [ ff15] 90758 [ 3fc82] 362871 [ ffe8a] 1570716 [ 40032a]
POPCNT instruction is not supported on this processor
PSHUFB instruction is not supported on this processor
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
По ссылке взяли следующий код для Intel:
код на СИ для Intel¶
Show Hidestatic const unsigned char g_pop_cnt256 = {
- define B2 n, n+1, n+1, n+2
- define B4 B2, B2, B2, B2
- define B6 B4, B4, B4, B4
B6, B6, B6, B6
};
static unsigned int POPCNT_Table(const unsigned char * buf, unsigned int len) {
unsigned int cnt = 0;
unsigned int ndwords = len / 4;
for(; ndwords; ndwords--) {
unsigned int v = (unsigned int)buf;
cnt += g_pop_cnt[v & 0xff] +
g_pop_cnt[(v >> 8) & 0xff] +
g_pop_cnt[(v >> 16) & 0xff] +
g_pop_cnt[v >> 24];
buf += 4;
}
if (len & 2) {
unsigned int v = (short)buf;
cnt += g_pop_cnt[ v & 0xff ] +
g_pop_cnt[ v >> 8 ];
buf += 2;
}
if (len & 1)
cnt += g_pop_cnt[ *buf ];
return cnt;
}
int main(int argc, char const *argv[])
{
unsigned int value = 1;
for (unsigned int i = 0; i < 262151000; i++) {
unsigned int res = POPCNT_Table((unsigned char*)&i, 4);
}
return 0;
}
код на ассемблере для Intel¶
Show Hide.file "popcnt.cpp"
.text
.type _ZL12POPCNT_TablePKhj, @function
_ZL12POPCNT_TablePKhj:
.LFB0:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5,
movl %esp, %ebp
.cfi_def_cfa_register 5
subl $16, %esp
movl $0, -16(%ebp)
movl 12(%ebp), %eax
shrl $2, %eax
movl %eax, -12(%ebp)
jmp .L2
.L3:
movl 8(%ebp), %eax
movl (%eax), %eax
movl %eax, -8(%ebp)
movl -8(%ebp), %eax
andl $255, %eax
movzbl _ZL9g_pop_cnt(%eax), %eax
movzbl %al, %edx
movl -8(%ebp), %eax
shrl $8, %eax
andl $255, %eax
movzbl _ZL9g_pop_cnt(%eax), %eax
movzbl %al, %eax
addl %eax, %edx
movl -8(%ebp), %eax
shrl $16, %eax
andl $255, %eax
movzbl _ZL9g_pop_cnt(%eax), %eax
movzbl %al, %eax
addl %eax, %edx
movl -8(%ebp), %eax
shrl $24, %eax
movzbl _ZL9g_pop_cnt(%eax), %eax
movzbl %al, %eax
addl %edx, %eax
addl %eax, -16(%ebp)
addl $4, 8(%ebp)
subl $1, -12(%ebp)
.L2:
cmpl $0, -12(%ebp)
setne %al
testb %al, %al
jne .L3
movl 12(%ebp), %eax
andl $2, %eax
testl %eax, %eax
je .L4
movl 8(%ebp), %eax
movzwl (%eax), %eax
cwtl
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
andl $255, %eax
movzbl _ZL9g_pop_cnt(%eax), %eax
movzbl %al, %edx
movl -4(%ebp), %eax
shrl $8, %eax
movzbl _ZL9g_pop_cnt(%eax), %eax
movzbl %al, %eax
addl %edx, %eax
addl %eax, -16(%ebp)
addl $2, 8(%ebp)
.L4:
movl 12(%ebp), %eax
andl $1, %eax
testl %eax, %eax
je .L5
movl 8(%ebp), %eax
movzbl (%eax), %eax
movzbl %al, %eax
movzbl _ZL9g_pop_cnt(%eax), %eax
movzbl %al, %eax
addl %eax, -16(%ebp)
.L5:
movl -16(%ebp), %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size _ZL12POPCNT_TablePKhj, .
.globl main
.type main, @function
main:
.LFB1:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
subl $24, %esp
movl $1, -8(%ebp)
movl $4, 4(%esp)
leal -8(%ebp), %eax
movl %eax, (%esp)
call _ZL12POPCNT_TablePKhj
movl %eax, -4(%ebp)
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE1:
.size main, .-main
.section .rodata
.align 32
.type _ZL9g_pop_cnt, @object
.size _ZL9g_pop_cnt, 256
_ZL9g_pop_cnt:
.byte 0
.byte 1
.byte 1
.byte 2
.byte 1
.byte 2
.byte 2
.byte 3
.byte 1
.byte 2
.byte 2
.byte 3
.byte 2
.byte 3
.byte 3
.byte 4
.byte 1
.byte 2
.byte 2
.byte 3
.byte 2
.byte 3
.byte 3
.byte 4
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 1
.byte 2
.byte 2
.byte 3
.byte 2
.byte 3
.byte 3
.byte 4
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 1
.byte 2
.byte 2
.byte 3
.byte 2
.byte 3
.byte 3
.byte 4
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 4
.byte 5
.byte 5
.byte 6
.byte 5
.byte 6
.byte 6
.byte 7
.byte 1
.byte 2
.byte 2
.byte 3
.byte 2
.byte 3
.byte 3
.byte 4
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 4
.byte 5
.byte 5
.byte 6
.byte 5
.byte 6
.byte 6
.byte 7
.byte 2
.byte 3
.byte 3
.byte 4
.byte 3
.byte 4
.byte 4
.byte 5
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 4
.byte 5
.byte 5
.byte 6
.byte 5
.byte 6
.byte 6
.byte 7
.byte 3
.byte 4
.byte 4
.byte 5
.byte 4
.byte 5
.byte 5
.byte 6
.byte 4
.byte 5
.byte 5
.byte 6
.byte 5
.byte 6
.byte 6
.byte 7
.byte 4
.byte 5
.byte 5
.byte 6
.byte 5
.byte 6
.byte 6
.byte 7
.byte 5
.byte 6
.byte 6
.byte 7
.byte 6
.byte 7
.byte 7
.byte 8
.ident "GCC: (Ubuntu/Linaro 4.7.2-2ubuntu1) 4.7.2"
.section .note.GNU-stack,"",@progbits
Параметры процессора:
Intel(R) Core(TM)2 Duo CPU E7500 @ 2.93GHz¶
Show Hideprocessor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 23
model name : Intel(R) Core(TM)2 Duo CPU E7500 @ 2.93GHz
stepping : 10
microcode : 0xa07
cpu MHz : 1600.000
cache size : 3072 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm constant_tsc arch_perfmon pebs bts aperfmperf pni dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm sse4_1 xsave lahf_lm dtherm tpr_shadow vnmi flexpriority
bogomips : 5866.46
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 23
model name : Intel(R) Core(TM)2 Duo CPU E7500 @ 2.93GHz
stepping : 10
microcode : 0xa07
cpu MHz : 1600.000
cache size : 3072 KB
physical id : 0
siblings : 2
core id : 1
cpu cores : 2
apicid : 1
initial apicid : 1
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe nx lm constant_tsc arch_perfmon pebs bts aperfmperf pni dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm sse4_1 xsave lahf_lm dtherm tpr_shadow vnmi flexpriority
bogomips : 5866.46
clflush size : 64
cache_alignment : 64
address sizes : 36 bits physical, 48 bits virtual
power management:
У нас получилось на нашем процессоре от Intel для 262151000 циклов время 0m3.436s, откуда получаем 20 тактов на цикл при частоте 1,6 ГГц.
Теоретически если в одном параграфе для мультиклеточного процессора сделать больше вычислений, то можно превзойти этот результат.
Правильно ли мы протестировали Intel?
| Makefile (61 Bytes) Makefile | |||
| popcnt (8.65 KB) popcnt | |||
| cpu_info.txt (1.61 KB) cpu_info.txt | |||
| popcnt.cpp (1.04 KB) popcnt.cpp | |||
| popcnt.s (4.45 KB) popcnt.s | |||
| time.txt (41 Bytes) time.txt |
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
Пока предварительно наилучшим образом влияет производство 4-6 вычислений в одном параграфе. Даже на P1 удалось добиться предварительно со 118 тактов уменьшения времени на цикл до 18 тактов (но откуда такая задержка мы ещё разбираемся). На P2 думаю можно ещё быстрее, время нужно найти свободное, чтобы тесты прогнать. Как сделаю, так и сообщу и приведу листинги. Т.е. сделать библиотеку, которая будет быстрее Intel работать можно на мультиклеточном процессоре в ближайшее время.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by sprin over 12 years ago
krufter_multiclet wrote:
У нас получилось на нашем процессоре от Intel для 262151000 циклов время 0m3.436s, откуда получаем 20 тактов на цикл при частоте 1,6 ГГц.
Теоретически если в одном параграфе для мультиклеточного процессора сделать больше вычислений, то можно превзойти этот результат.
Правильно ли мы протестировали Intel?
Чем вас не устроили уже готовые тесты Benchmarking CRC32 and PopCnt instructions -> Download the code MSVC, 30 KB ? К тому же там подсчёт идет именно через такты, а не через таймер.
krufter_multiclet wrote:
Пока предварительно наилучшим образом влияет производство 4-6 вычислений в одном параграфе. Даже на P1 удалось добиться предварительно со 118 тактов уменьшения времени на цикл до 18 тактов (но откуда >такая задержка мы ещё разбираемся). На P2 думаю можно ещё быстрее, время нужно найти свободное, чтобы тесты прогнать. Как сделаю, так и сообщу и приведу листинги.
Хорошо.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
Мы хотели проверить готовые тесты и получить похожие результаты. Тесты готовые насколько я понимаю 3-х летней давности, поэтому хотелось бы повторить их и получить результат в тактах на конкретных процессорах. Но после проверки приведённой функции мы получили 20 тактов, а не 6-7. Может мы что-то не правильно посчитали для процессора Intel, либо тест проводился на процессоре с аппаратной поддержкой popcnt. В принципе можно автору тех тестов написать и спросить на каком именно процессоре он их проводил и почему у нас результаты отличаются.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by sprin over 12 years ago
krufter_multiclet wrote:
Мы хотели проверить готовые тесты и получить похожие результаты. Тесты готовые насколько я понимаю 3-х летней давности, поэтому хотелось бы повторить их и получить результат в тактах на конкретных процессорах. Но после проверки приведённой функции мы получили 20 тактов, а не 6-7. Может мы что-то не правильно посчитали для процессора Intel, либо тест проводился на процессоре с аппаратной поддержкой popcnt. В принципе можно автору тех тестов написать и спросить на каком именно процессоре он их проводил и почему у нас результаты отличаются.
Что-то я не понимаю, я дал ссылку на исходный код для тестирования, надо только собрать, запустить и получить результат. Я выше приводил результат для Intel(R) Celeron(R) D CPU 3.06GHz, они получены по программе автора (+ несколько доп. тестов), которая находится на той же странице, сразу перед комментариями.
RE: Ассемблер. Реализация POPCNT для MC P1 - Added by krufter_multiclet over 12 years ago
Ну вот запустил на своём процессоре:
Pentium Dual Core(R) CPU 5700 3.00GHz¶
Show Hide250 1025 4103 16384 65537 262151 1048576
Dilip Sarwate 1845 [f0c40ca9] 6810 [7b30d248] 26535 [f2a67bc2] 105225 [ab540a8f] 421590 [1e3904dc] 1695945 [500bdca5] 6819195 [8b91984d]
Richard Black 1935 [f0c40ca9] 7275 [7b30d248] 28425 [f2a67bc2] 112875 [ab540a8f] 438810 [1e3904dc] 1742475 [500bdca5] 6963480 [8b91984d]
Slicing-by-4 1035 [f0c40ca9] 3585 [7b30d248] 13635 [f2a67bc2] 52605 [ab540a8f] 209655 [1e3904dc] 837750 [500bdca5] 3347040 [8b91984d]
Slicing-by-8 765 [f0c40ca9] 2310 [7b30d248] 8430 [f2a67bc2] 33150 [ab540a8f] 131550 [1e3904dc] 525825 [500bdca5] 2103330 [8b91984d]
CRC32 instruction is not supported on this processor
250 1025 4103 16384 65537 262151 1048576
Bit Hacks 840 [ 3d5] 2685 [ 100a] 9990 [ 4012] 38970 [ ff15] 155280 [ 3fc82] 619575 [ ffe8a] 2462430 [ 40032a]
Table 750 [ 3d5] 2565 [ 100a] 9015 [ 4012] 35295 [ ff15] 140505 [ 3fc82] 561225 [ ffe8a] 2245005 [ 40032a]
SSE2 405 [ 3d5] 795 [ 100a] 2280 [ 4012] 8205 [ ff15] 32235 [ 3fc82] 128085 [ ffe8a] 511545 [ 40032a]POPCNT instruction is not supported on this processor
SSSE3 330 [ 3d5] 600 [ 100a] 1575 [ 4012] 5175 [ ff15] 21360 [ 3fc82] 84120 [ ffe8a] 335415 [ 40032a]
Т.е. получается для теста Table при 262151 итерации 561225 тактов. Откуда получаем, что на одну итерацию требуется чуть больше 2 тактов. С этим результатом мы несогласны. Мы считаем, что время в тесте измеряется неправильно.
Вот в этих функциях:
UINT64 inline GetRDTSC() {
__asm {
; Flush the pipeline
XOR eax, eax
CPUID
; Get RDTSC counter in edx:eax
RDTSC
}
}
UINT Benchmark(CRC_FUNC func, const BYTE * buffer, SIZE_T length, OUT RES & result) {
UINT min_time = UINT_MAX;
RES res = 0;
for (UINT j = 0; j < 20; j++) {
UINT64 start_time = GetRDTSC();
res = func(buffer, length);
UINT time = (UINT)(GetRDTSC() - start_time);
min_time = min(min_time, time);
}
result = res;
return min_time;
}
Мы видим приведение 64-х разрядного числа к 32-х разрядному, в результате чего можем получить неверный результат по тесту процессора Intel.
Просто прежде чем что-то запускать мы анализируем верно ли работает тест и верно ли идёт подсчёт времени. Перепишем сейчас подсчёт времени как нужно и посмотрим на результат.