Forums » Мультиклеточная архитектура »
Оптимизация архитектуры
Added by krufter_multiclet about 11 years ago
Предложения по оптимизации мультиклеточной архитектуры для следующих ревизий процессоров можно размещать в данной теме.
Текущий список запланированных оптимизаций:
Общее:
1) GPIO с несколькими альтернативными функциями
2) Блок семафоров аппаратный
3) Присваивание процессору индивидуального номера прямо в кристалле
4) Доработка системы сброса (некоторая избирательность по системным настройкам, дебагеру)
5) Отдельное тактирование разных веток периферийной шины
6) Домены по питанию
7) Вывод тактовой частоты процессора с делителем
8) Одно напряжение питания
9) Аппаратный делитель
10) Обмен результатами между параграфами без памяти
11) Возможность использовать в качестве первого аргумента команды регистры, косвенную адресацию
12) Отправка результата команды сразу в регистр
13) Развязка записи в РОН от complete
14) Рассмотреть вопрос зависимости не только по данным, но и по факту выполнения команд
15) Доступ к флагам, например @1.z - получение Zero flag
Периферия:
1)Ethernet 10/100 MAC+PHY (2 канала)
2)Доработка RTC, ШИМ
3)Аппаратный блок CRC (Blake2, ГОСТ Р 34.11-2012)
4)USB PHY (Device + Host) 2.0, 480 Мбит/с
5)Температурный датчик
6)Загрузчик по UART + защищенные режимы
7)Шифрование по ГОСТ89 или ГОСТ-2015
8)Доработать SPI для повышения частоты работы процессора
Replies (146)
RE: Оптимизация архитектуры - Added by VaalKIA over 10 years ago
Yaisis wrote:
VaalKIA wrote:
Не согласен, практика показала, что универсальность важнее мифической экономии транзисторов. Фактически, предлагается сделать исключение из правил, а любые исключения очень усложняют жизнь всем. Не надо самим себе создавать трудности, а потом заниматься заходом солнца в ручную.
Это я не согласен с вами. Любой программист при оптимизации кода старается избавиться от инструкций деления и заменить их умножением, т.к. умножение примерно в 30 раз быстрее, чем инструкция деления. Таким образом теоретически в коде присутствует больше инструкций умножения, чем деления. Сама инструкция деления, наверно, по схеметехнике сложнее инструкции умножения и следовательно занимает больше транзисторов. Теперь представим, что при текущем техпроцессе в процессор помещается 64 клетки и допустим, если мы урежем и сделаем инструкции деления не в каждой клетке, а только в четверти из них, то сможем увеличить количества клеток в процессоре в 2 раза, т.е. их станет уже 128. Но с учётом того, что в коде больше инструкций умножения, чем деления, мы не потеряем в производительности, а наоборот ускорим её примерно в 2 раза.
Про 30 раз в скорости, и замену деления: умножением со сдвигом - это просто смешно (ну можно же то же самое делать аппартно, если есть просчёты в архитектуре, то при чём здесь это?).
Потом идёт бла-бла-бла, 2 раза 128 штук...
Прочтите вот это: http://habrahabr.ru/company/intel/blog/158223/ (жизнь в эпоху тёмного кремния. В кратце, при переходе на более тонкие нормы, заполняют много места "мусорными" транзисторами, ну а можно было бы схемой деления)
Возьмите к примеру матричные преобразования, которые используются в 3D-графике и ещё много где -- там везде используются в основном одни умножения со сложениями.
Конечно, если урезать инструкции деления например, то надо смотреть, какой положительный эффект они могут дать. Как в моём примере(от балды) положительный эффект был в виде увеличения количества клеток в 2 раза, а это было бы круто, но если в реальности таким образом будет добавлено например всего 5-лишних клеток, то может и нет смысла ничего урезать, т.к. мы потеряем 48 делений и получим всего 5 умножений, что не целесообразно(да и первый вариант я тоже не знаю целесообразен он или нет) -- это всё надо оценивать.
Но при этом, почему-то ввели MMX, что бы не терять на декодировании инструкций и сразу делать умножение со сложением, а не выкинули деление, не?
Конечно хотелось бы иметь полноценные клетки, но в данном случае надо смотреть реальности в глаза и принимать соответствующие решения, которые в целом могут улучшить процессор.
Или - ухудшить.
Чем меньше схема(клетка) занимает, тем больше схем(клеток) они смогут поместить в кристалл.
Это слишком упрощённо, что бы принимать это во внимание.
поэтому огрызки не дают почти ничего, по сравнению с полнофункциональными блоками.
И тут не верно.
Допустим есть в коде очень непопулярная инструкция, например получения количества тактов пройденный процессором с момента его старта. Какой смысл плодить такую инструкцию во всех клетках, если она очень редко используется в коде ?
Ответил в другом письме.
Возьмите хотя бы опыт АМД, которая ну как только не старалась подрезать свои ядра, слепить из двух одно или не до конца разделить ядро на два, в итоге это всё не сыграло.
Она не подрезала ядра, а наоборот увеличивала их. Она в одно ядро вместо одного целочисленного блока вставила 2, т.к. наличие дополнительного блока приводило к увеличению кристалла всего на 10%, но в целочисленных вычислениях могло повысить производительность в 2 раза.
Только она нечестно называла процессоры, например 8-ядерными, когда в реальности там было полноценных всего 4 ядра, поэтому конечно это можно расценить, как урезание ядра.
И не взлетело не из-за такого метода, а из-за самой неудавшейся архитектуры, да и блоков FPU тоже должно быть много -- у Интел их больше было и Интел выигрывал, да и сама архитектура у него пока лучше.
Мне вообще не нравятся FP, при современном разрядном слове, давно пора уже переходить на аппартные дроби, диапазон уже достаточный. Ну а по поводу АМД, почитатйте отзывы о современнных Пледривер и о том, что ждут от Зен. Соглашусь с вами - не важно от какого конца палки двигаться, если оба результата показывают, что в итоге ни раздутое ядро ни урезанное - не круто.
И да, любую инструкцию аппаратно можно выполнить за один такт.
Операция умножения на Интеле аппаратно выполняется за 3 такта.
Операция деления на нём же аппаратно -- примерно за 40 тактов.
Есть там и другие более прожорливые операции.
А зачем оптимизировать инструкцию, которую заменяют умножением со сдвигом? скажите спасибо, что её вообще не выкинули, ради совместимости. Как говорится: нет спросу, нет и завозу.
у интел была похожая история, особенно с гипер-треадингом, который не то что бы реально нужен.
Гипер-треадинг -- это очень полезная технология и он реально нужен.
Он не даёт вычислительным блокам простаивать и загружает их из других потоков.
Для сравнения, я делал многопоточную программу и запускал её на своём 4-ядерном процессоре с гипер-треадингом, т.е. в сумме было 8 ядер, 4 из которых виртуальные.
При разбитии процесса вычисления на 4 потока была получена производительность, соответствующая производительности процессора без гипер-треадинга и соответствующая производительности 4-ядерному процессору.
При разбитии процесса вычисления на 8 потоков была получена производительность, равная 6-ядерному процессору, т.е. 4 виртуальных потока принесли производительность равную 2-м дополнительным ядрам, которых в реальности нет в процессоре.
В результате при количестве транзисторов в процессоре примерно равным 4-ядерному процессору, гипер-треадинг дал производительность 6-ядерного процессора, что очень круто и очень полезно.
Ещё полезней, когда программист делит задачи по ядрам, а потом выясняется что все ядра отсрелялись и ждут последного, который гипер и у которого скорость в 10 раз ниже. Нет, на практике, действительно, выгода - есть, но только надо учитывать, что есть такая вещь как ОС, которая жрёт просто тонну ресурсов, и её же обеспечение правильной работы треадинга на этом фоне просто теряется. Если же рассматривать в чистом виде, то лучше бы они простаивали, потому что не бывает бесплатного сыра и замедляется работа основного ядра во время работы гипертреадинга и тепловыделение увеличивается, и кеш дербанится и есть ещё куча нюансов, проще было бы ускорить основое ядро, вместо всей этой вумной обвязки (которая больше, чем "простаивающие" транзисторы). Но что это!? Оказывается архитектура x86 это такой монстр, что там, практически уже встроен искуственный интеллект, так что гипер-треадинг мы полчили почти бесплатно, но стоит ли повторять этот подвиг в нормальном проце.. - сомневаюсь. Тут как раз тот случай, когда нет худа, без добра. уж очень много они навертели, что бы вымученную архитектуру ускорить, но это же их и погубит, потому что в сравнении с нормальными архитектурами они просто - монстр, где всё надо выкинуть, а остальное - переделать (и АРМ c MIPS, наконец-таки стали популярны и скоро эта тема будет закрыта, особенно в свете всё большей кроссплатформенности ПО).
Клетки же при загрузки в себя команд будут по своему индексу считывать сразу(или последовательно) по три разные инструкции из этих трёх буферов.
Это какая-то вариация VLIW по типу Итаниума и Трансметы
Это к VLIW`у не имеет никакого отношения и ни капли на него не похоже даже.
Это возможное развитие их архитектуры, при этом достаточно простое решение предложено, но имеющее свои недостатки, которые надо обдумать и которые я не назвал(разработчики об них итак знают).
Сейчас при загрузке инструкций в буфер клетки, она также считывает последовательно инструкции из какого-то входного буфера, было лишь предложено усовершенствовать входной буфер, чтобы в клетку попадали разные инструкции для разных функциональных блоков и таким образом загрузка клетки была бы больше.
Идеология VLIW примерно такая: у нас есть в ядре несколько независмых блоков, каждый может исполнять свой тип инструкций, так давайте сделаем мега комманду, которую сразу наполняют инструкциями для каждого из блоков. Если такой инструкции нет, в данный момент, ну так и так бы блок же простаивал! А потом компилятор пусть пытается на каждую такую мега инструкцию набить её независимыми коммандами (фактически это пра-пра-пра-дедушка параграфов, на сколько я понимаю), это же лучше чем x86 где сам проц в рантайме парсит.
Ну так, то же и предлагаете - повысить зависимость программы от архитектуры, добавили какие-нибудь дроби и пошли лесом все программы, потому что разных инструкций теперь не три, а четыре.
А про какой-то входной буфер, наверное понимается Гарвардская архитектура, которая в отличии от Фоннеймовской, разделяет комманды и данные и поэтому считывает одновременно с коммандой операнды, на заре компьютерной эры это было ужасное расточительство, ведь память измерялась считанными байтами, а когда данные не лазут, а блок инструкций почти пустой... в общем, теперь эту штуку используют в кешах, которые продвинуты, если они раздельны.
То, что я предложил -- это по эффективности должно быть, как гипер-треадинг(но для одного потока, т.к. многопоточности у них нет) и по сути направлено на тоже самое -- на то, чтобы блоки процессора(или блоки клетки в данном случае) не простаивали.
Чем больше блоков будет загружено в каждый момент времени, тем больше производительность процессора.
Это то же самое, что автострада.. тут недавно в Китае, вроде бы, 50 полос намертво встали, хотя загруженны - полностью, но может лучше, всё же что бы они ехали и не мешали друг другу?
практика показала, что очень сильно привязывается к конкретному ядру или поколению процессора и надо всё перекомпилировать при малейших изменениях в железе.
Практика такого не показывала никогда.
В Эльбрусе VLIW и как я читал, в нём используется промежуточный код, которые подстраивается под любую модель процессора Эльбрус и этот промежуточный код не привязан ни к одной архитектуре. Так что нет такого недостатка у VLIW и всё зависит только от техники реализации.
Невозможность эффективно задействовать все вычислительные блоки уже зависит от самого кода, а не от какой-то там привязки к процессору, которой там нет.
Я VLIW или что-то похожее на него не предлагал ни разу тут.
Выше я ответил, с Эльбрусом, к сожалению, не знаком, надесь наши что-то придумали. А вот, про Трансмету вы почитайте, что особенно актуально, в силу того, что она не взлетела, да и Итаниум всеми силами тянет такой гигант, но результат, для таких услилий - весьма посредственный, а когда-то они x86 закрывали, говорили-то что 64 бита - не будет, мы вам Итаниум сделали - это будуее, не припомните? Они бы уже по миру пошли, если бы это был не блеф.
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
VaalKIA wrote:
"Плодить в клетках" это термин ни о чём. То что инструкция доступна на исполнение клеткой не говорит о том, что в железе реализация этой инструкции там же.
Если инструкция доступна на исполнение клеткой, то это значит, что клетка уже должна понимать данную инструкцию, а это дополнительные транзисторы. В предложенном же варианте даже команду резервировать не надо.
То что предлагается как чтение из памяти, это фактически регистр, имя которого не зашито в саму инструкцию а передаётся как параметрМожно и регистр сделать. Я выражался в терминах Мультиклета -- там буферы с тегами. Тут был бы дополнительный буфер с адресом, который можно и регистровым массивом назвать.
и никакой порчи "линейного буфера памяти" в угоду сокращению количества инструкций не нужно.
Никакой порчи итак нет, но если бы была, то лучше выбрать сокращение количества инструкций, т.к. под их кодировку не надо будет отводить специальные биты.
Ну как бы инфо комманда в процессорах есть, но не зачем для этого портить адресацию, можно и в стек запихнуть.
Если такая команда есть, то можно и ей одной воспользоваться и передавать туда адрес буфера или регистра в качестве параметра. Эта инфо команда будет работать со своим инфобуфером и таким образом её внутренние адреса не будут пересекатся с адресами остальной памяти.
Да нет никаких проблем реализовать это в схемотехнике, и в драгоценные биты кода комманды все операнды тоже не надо запихивать (регистр можно передать как параметр), их впролне хватит, что бы не экономить на спичках и не портить адресное пространство.
Никто не предлагал ничего портить, под буфером имелась ввиду выделенная память в процессоре, которая никак не пересекается с остальной памятью.
А нужные адреса можно найти в начальных адресах, которые ложаться в область биоса обычно и служат примерно для тех же целей. Адреса памяти начинаются с более высоких адресов.
По поводу даты, тут вообще шикарная история, на самом деле достаточно всё того же счётчика тактов и хранение в виде строки, это полная лажа, от которой одни проблемы, не говоря уже о том, что реально в таком формате время нужно только на выводе, и это операция, которая вообще не требует оптимизаций, поэтому делать "предрасчёт" для дат и мучиться потмо с вычислениями... Но все именно этим и занимаются, почему? Потому что качество тактовых генераторов не достаточно, что бы отсчитывать время, там уже в сутки плывёт всё на секунды, поэтому все имеют гемморой и пишут время в некомпьютерном формате и счтитают в нём же.
Я не предлагал конкретный способ хранения даты. Я только предложил механизм, как это можно реализовать, а формат может быть любой.
на самом деле достаточно всё того же счётчика тактов
Не достаточно.
Счётчик тактов отсчитывает количество пройденных тактов с момента запуска компьютера и после каждой перезагрузки сбрасывается.
Он имеет ограниченный размер.
Ну конечно, если вы имели ввиду то, чтобы его не сбрасывать никогда и сделать достаточно большим для хранении большого количество тактов, которого хватит на много веков, то может тогда и достаточно.
Я думаю, что лучше дату не хранить таким способом.
и хранение в виде строки
В виде строки хранить глупо, другое дело хранить в числах.
Сложнее всего разобраться в написанном.. но сдаётся мне тут описываются какие-то функции блочной работы с памятью (заполнение шумом), присущие DMA и 64кб случайных чисел это часто, уже достаточно.
Если вам сложно разобраться в написанном, то просто пропустите этот пункт и не надо догадок по тому, чего не поняли.
Нет там никаких функций по блочной работе с памятью.
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
VaalKIA wrote:
Про 30 раз в скорости, и замену деления: умножением со сдвигом - это просто смешно (ну можно же то же самое делать аппартно, если есть просчёты в архитектуре, то при чём здесь это?).
Не то число написал, примерно в 10 хотел написать, ошибся.
Вывод делался из того, что у Интела инструкция умножения выполняется за 3 такта, а инструкция деления примерно за 40, т.е. 40/3 = 13.33 раза.
Потом идёт бла-бла-бла, 2 раза 128 штук...
Я же написал, что "от балды" -- это был просто пример, а реально есть ли эффективность или нет -- это надо оценивать.
Я никогда не говорил, что сразу надо что-то урезать там.
Прочтите вот это: http://habrahabr.ru/company/intel/blog/158223/ (жизнь в эпоху тёмного кремния. В кратце, при переходе на более тонкие нормы, заполняют много места "мусорными" транзисторами, ну а можно было бы схемой деления)
Если бы можно было бы, то заполнили.
А так же можно было бы дополнительными клетками без схемы деления.
Но при этом, почему-то ввели MMX, что бы не терять на декодировании инструкций и сразу делать умножение со сложением, а не выкинули деление, не?
Вы примеры не в тему приводите.
Узнайте для чего вводят SIMD команды и поймёте для чего ввели MMX.
Ситуация с MMX никак не относится к моему примеру про матричные преобразования.
И в Интеле не так много вычислительных устройств, чтобы выкидывать деление, а вот если брать в пример графические карты, в которых под 4000 шейдерных процессоров, то там выкидывают деление, чтобы реализовать столько процессоров.
Возьмём в пример старую видеокарту АМД ещё со VLIW-архитектурой, в которой команда состояла из 5 инструкций и только 5-я могла выполнять деление.
В современных видеокартах не знаю, как с этим делом.
Конечно хотелось бы иметь полноценные клетки, но в данном случае надо смотреть реальности в глаза и принимать соответствующие решения, которые в целом могут улучшить процессор.
Или - ухудшить.
Только улучшить, потому что урезаться всё будет только в том случае, если это принесёт пользу, иначе всё останется так, как есть.
Я не зря каждый раз пишу, что прежде чем что-то делать, надо сначала произвести оценку и узнать целесообразность внесения таких изменений.
Чем меньше схема(клетка) занимает, тем больше схем(клеток) они смогут поместить в кристалл.
Это слишком упрощённо, что бы принимать это во внимание.
Посмотрите на шейдерные процессоры в видеокарте и посмотрите также, сколько их поместилось в данном процессоре. Их разработчики это всё приняли во внимание.
Точно также, как и последний Intel Xeon Phy -- он тоже урезан по сравнению с обычными десктопными процессорами и благодаря этому вмещает в себя 72 ядра, но он также будет в варианте обычного CPU. И насколько я знаю, в нём нет даже MMX-а, который вы привели выше, там только AVX оставили.
Мне вообще не нравятся FP, при современном разрядном слове, давно пора уже переходить на аппартные дроби, диапазон уже достаточный. Ну а по поводу АМД, почитатйте отзывы о современнных Пледривер и о том, что ждут от Зен. Соглашусь с вами - не важно от какого конца палки двигаться, если оба результата показывают, что в итоге ни раздутое ядро ни урезанное - не круто.
Я знаю, какие там отзывы и также знаю примерное строение данных процессоров(по информации из интернета).
А зачем оптимизировать инструкцию, которую заменяют умножением со сдвигом? скажите спасибо, что её вообще не выкинули, ради совместимости. Как говорится: нет спросу, нет и завозу.
Тут я не понял о чём вы.
Вы хоть бы пример привели, что за инструкция такая ?
Может вы имели ввиду то, что иногда умножение или деление на число кратное двум заменяют сдвигом ?
Ещё полезней, когда программист делит задачи по ядрам, а потом выясняется что все ядра отсрелялись и ждут последного, который гипер и у которого скорость в 10 раз ниже.
Такого не может быть. Процессоры не так функционируют.
Не может одна задача быть нагружена на виртуальное ядро и при этом чтобы остальные простаивали, т.к. виртуальные ядра используются тогда, когда все реальные заняты. Если в системе в сумме 8 ядер и 4 из них виртуальные, то при загрузке всего 4 потоков они всегда будут нагружать реальные ядра, а не виртуальные. Виртуальные нагружают только при количестве потоков большем, чем количество реальных ядер.
Любой поток на виртуальном ядре становится потоком на реальном ядре при освобождении реального ядра. Даже всё намного проще, но долго объяснять.
Нет, на практике, действительно, выгода - есть, но только надо учитывать, что есть такая вещь как ОС, которая жрёт просто тонну ресурсов, и её же обеспечение правильной работы треадинга на этом фоне просто теряется. Если же рассматривать в чистом виде, то лучше бы они простаивали, потому что не бывает бесплатного сыра и замедляется работа основного ядра во время работы гипертреадинга и тепловыделение увеличивается, и кеш дербанится и есть ещё куча нюансов, проще было бы ускорить основое ядро, вместо всей этой вумной обвязки (которая больше, чем "простаивающие" транзисторы). Но что это!? Оказывается архитектура x86 это такой монстр, что там, практически уже встроен искуственный интеллект, так что гипер-треадинг мы полчили почти бесплатно, но стоит ли повторять этот подвиг в нормальном проце.. - сомневаюсь. Тут как раз тот случай, когда нет худа, без добра. уж очень много они навертели, что бы вымученную архитектуру ускорить, но это же их и погубит, потому что в сравнении с нормальными архитектурами они просто - монстр, где всё надо выкинуть, а остальное - переделать (и АРМ c MIPS, наконец-таки стали популярны и скоро эта тема будет закрыта, особенно в свете всё большей кроссплатформенности ПО).
Такого бреда ещё не читал нигде.
Но скажу, что технология аналогичная гипер-треадингу полезна абсолютно для любого процессора. И для АРМ-ов и для МИПС-ов. И для Эльбрусов. И для Мультиклета, если они реализуют многопоточность. Только я думаю, что в Мультиклете она может появиться сама собой, без её умышленного создания.
Полезна она потому, что она старается заполнить работой по-максимуму имеющиеся ресурсы процессора. Без разницы сколько вы там ядер воткнуть сможете, гипер-треадин он повышает КПД каждого ядра и при этом занимает меньше места на кристалле, чем размещение дополнительных ядер, т.е. вы можете воткнуть в кристалл ядер под завязку так, что больше ядер у вас уже никак не влезет, но гипер-треадинг-то ещё влезет, а с ним КПД процессора будет выше и процессор будет производительней, чем без него.
Современная же x86 от CISC-архитектуры оставила только набор инструкций и на первом этапе CISC команды преобразуются в RISC команды и выполняются внутри на RISC-ядре.
Клетки же при загрузки в себя команд будут по своему индексу считывать сразу(или последовательно) по три разные инструкции из этих трёх буферов.
Это какая-то вариация VLIW по типу Итаниума и Трансметы
Это к VLIW`у не имеет никакого отношения и ни капли на него не похоже даже.
Это возможное развитие их архитектуры, при этом достаточно простое решение предложено, но имеющее свои недостатки, которые надо обдумать и которые я не назвал(разработчики об них итак знают).
Сейчас при загрузке инструкций в буфер клетки, она также считывает последовательно инструкции из какого-то входного буфера, было лишь предложено усовершенствовать входной буфер, чтобы в клетку попадали разные инструкции для разных функциональных блоков и таким образом загрузка клетки была бы больше.
Идеология VLIW примерно такая: у нас есть в ядре несколько независмых блоков, каждый может исполнять свой тип инструкций, так давайте сделаем мега комманду, которую сразу наполняют инструкциями для каждого из блоков. Если такой инструкции нет, в данный момент, ну так и так бы блок же простаивал! А потом компилятор пусть пытается на каждую такую мега инструкцию набить её независимыми коммандами (фактически это пра-пра-пра-дедушка параграфов, на сколько я понимаю), это же лучше чем x86 где сам проц в рантайме парсит.
Я не предлагал делать мегакоманд, а эффективная нагрузка вычислительных блоков присуща любой современной архитектуре и при этом к VLIW большинство из них не имеет отношения.
Да и не такая идеология у VLIW, а другая -- чтобы не делать суперскаляр нужно распараллелить инструкции на стадии компиляции и объединить их в широкое командное слово(VLIW), инструкции из которого можно выполнить параллельно. Таким образом параллельно можно выполнять больше инструкций, т.к. аппаратно почти невозможно создать аналогичный по эффективности блок суперскаляра. Плюс идёт экономия кучи транзисторов, так как многое выполняется на стадии компиляции, а не выполнения.
Ну так, то же и предлагаете - повысить зависимость программы от архитектуры, добавили какие-нибудь дроби и пошли лесом все программы, потому что разных инструкций теперь не три, а четыре.
В моём предложении нет компилятора. VLIW -- это широкое командное слово, а в коде -- это несколько команд, объединённых в группу - объединяет их компилятор.
Если вы в моём предложении увидели "похожесть" на VLIW-архитектуру, то точно также я могу подумать, что по тем же признакам вы можете увидеть данную похожесть в любой современной архитектуре, т.к. все они пытаются максимально загрузить работой все свои функциональные блоки.
А про какой-то входной буфер, наверное понимается Гарвардская архитектура, которая в отличии от Фоннеймовской, разделяет комманды и данные и поэтому считывает одновременно с коммандой операнды, на заре компьютерной эры это было ужасное расточительство, ведь память измерялась считанными байтами, а когда данные не лазут, а блок инструкций почти пустой... в общем, теперь эту штуку используют в кешах, которые продвинуты, если они раздельны.
Речь шла об Мультиклете и об их входном буфере.
Или у них нет буфера из которого считываются инструкции ?
Выше я ответил, с Эльбрусом, к сожалению, не знаком, надесь наши что-то придумали. А вот, про Трансмету вы почитайте, что особенно актуально, в силу того, что она не взлетела, да и Итаниум всеми силами тянет такой гигант, но результат, для таких услилий - весьма посредственный, а когда-то они x86 закрывали, говорили-то что 64 бита - не будет, мы вам Итаниум сделали - это будуее, не припомните? Они бы уже по миру пошли, если бы это был не блеф.
Недостатки же Трансметы и Интела происходят из-за неправильной реализации -- они могли сделать также, как в Эльбрусе, но не сделали.
Повторю ещё раз, что моё предложение никак не относиться к VLIW-архитектуре.
RE: Оптимизация архитектуры - Added by krufter_multiclet over 10 years ago
Yaisis wrote:
Речь шла об Мультиклете и об их входном буфере.
Или у них нет буфера из которого считываются инструкции ?
В процессоре Мультиклет R1 входным буфером является память программ или память данных, откуда команды выбираются и затем декодером сразу помещаются в буфер на исполнение, т.е. нет необходимости в чем-то промежуточном.
RE: Оптимизация архитектуры - Added by EviLOne over 10 years ago
При всем уважении к отписавшимся, но сейчас ваш диалог выглядит как деление шкуры не убитого медведя. Как уже было сказано выше, даже на цифрового стража было тяжело выбить финансирование. На данный момент главным тормозом является факт отсутствия полноценного компилятора, что опять же обсуждалось выше и ни один раз. Без него тяжело представить ту нишу, на которую будет стремиться микропроцессор.Затачивать архитектуру нужно после определения целей под которые он будет работать. Пока такого мной не было замечено (если не прав, то сообщите), разработчики правда обещали делиться по мере доступности некоторыми интересными результатами и материалами внутренних исследований.
Единственное что могу сказать, что лично мне тяжело представляются алгоритмы, на которых будет эффективное исполнение от 8 клеток в одном параграфе. По тому при наличии, допустим, 64 клеток, их придется делить на большое количество групп. По тому, весь этот массив можно поделить на 8 блоков по 8 клеток, объединение/разделение клеток на группы возможно в пределах одного блока. Таким образом, мы сразу можем обрабатывать 8 потоков, каждый из которых можно будет раздробить еще до 8 потоков. А равновесность блоков по возможностям можно определять в зависимости от задач под которую архитектура будет заточена. (сетевые устройства и системы связи, терминальные устройства, обработка сигналов, физический ускоритель, системы управления или еще чего душе угодно). Лично мне (и за два года выбил внимание у ведущий конструкторов предприятия) интересно его видеть в обвязке с хорошей и многочисленной периферией (посмотреть те же TI процы или на худой конец миландр в том числе и с перспективными решениями), для использования в различных системах управления или рабочей вычислительной лошадки во встраиваемых системах.
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
krufter_multiclet wrote:
В процессоре Мультиклет R1 входным буфером является память программ или память данных, откуда команды выбираются и затем декодером сразу помещаются в буфер на исполнение, т.е. нет необходимости в чем-то промежуточном.
Т.е. клетки берут данные напрямую из памяти.
Тогда мой вариант не подойдёт.
Надо придумывать другое решение по равномерному заполнению разными командами буфера клетки.
RE: Оптимизация архитектуры - Added by VaalKIA over 10 years ago
Yaisis wrote:
VaalKIA wrote:
"Плодить в клетках" это термин ни о чём. То что инструкция доступна на исполнение клеткой не говорит о том, что в железе реализация этой инструкции там же.
Если инструкция доступна на исполнение клеткой, то это значит, что клетка уже должна понимать данную инструкцию, а это дополнительные транзисторы. В предложенном же варианте даже команду резервировать не надо.
Да, но что понимается под "пониманием клеткой"? На практике, есть декодер операндов и самой инструкции и транзисторные блоки, которые оперируют с кратким наименованием ячеек (регистрами) или самой памятью, да даже вообще - с чем угодно. Поскольку инструкции исполняются клетками, то на декодерах не сэкономишь (хотя не факт - тоже можно, но слишком большая вариативность, так что - сложно), и на каждую клетку свой декодер, но вот как раз исполнительный блок, может быть общим для определённого вида инструкции.
То что предлагается как чтение из памяти, это фактически регистр, имя которого не зашито в саму инструкцию а передаётся как параметрМожно и регистр сделать. Я выражался в терминах Мультиклета -- там буферы с тегами. Тут был бы дополнительный буфер с адресом, который можно и регистровым массивом назвать.
Я не спорю, лишь определяю предметную область. Де факто, можно взять Instruction Set Architecture (ISA) и посмотреть как это кодируется в битах и будет понятно, что на уровне кодов, регистры это те же ячейки памяти, просто зашитые сразу в инструкцию, а не передающиеся как параметры.
и никакой порчи "линейного буфера памяти" в угоду сокращению количества инструкций не нужно.
Никакой порчи итак нет, но если бы была, то лучше выбрать сокращение количества инструкций, т.к. под их кодировку не надо будет отводить специальные биты.
Эээ.. ну если вариативность инструкций 8 бит, к примеру, и 1 бит мы резервируем, как маркер, что в инструкцию забито два регистра из 8 возможных, то это получается 128 инструкций, помимо всего ДВУХ инструкций, оперирующих с двумя регистрами (1 бит (регистры зашиты или нет) + 1 бит (вид опреации) + 3 бита (регистр) + 3 бита (регистр)). Именно это я подразумеваю под сокращением набора инструкций.
Ну как бы инфо комманда в процессорах есть, но не зачем для этого портить адресацию, можно и в стек запихнуть.
Если такая команда есть, то можно и ей одной воспользоваться и передавать туда адрес буфера или регистра в качестве параметра. Эта инфо команда будет работать со своим инфобуфером и таким образом её внутренние адреса не будут пересекатся с адресами остальной памяти.
Где зашит исходник инфы - глубоко пофиг, это реализуется схемой процесора, на логическом уровне это можно игнорировать. А вот, куда копировать - это будет целое семейство кодов (каждый бит МОЖЕТ уменьшить общее семейство кодов вдвое, что бы сказать, что это инфо, нужен хотя бы один бит, и что бы сказать, что дальше идёт адрес - ещё бит, либо зашить в саму инструкции подобие наименование регистра(это ещё бита три)). Поэтому я и говорю, что не надо давать лишнюю нагрузку на семейство кодов.
Никто не предлагал ничего портить, под буфером имелась ввиду выделенная память в процессоре, которая никак не пересекается с остальной памятью.
А нужные адреса можно найти в начальных адресах, которые ложаться в область биоса обычно и служат примерно для тех же целей. Адреса памяти начинаются с более высоких адресов.
Для того, что бы взять информацию из этой специальной памяти, процессору достаточно знать, что это спец комманда (хватит и одного бита, в определённом разряде, значит меньше чем вдвое сокращение), а вот, если из специальной области памяти читать потом, то это надо как-то обозначить, как я уже говорил, это подобно появление нового регистра, де факто это ещё 3-4 бита на то что бы сказать что это за регистр. Лиди давно уже придумали хороший вариант: данные инфо просто пишутся в стек при вызове подобной комманды, мы и в размерах не ограниченны и не надо явно передвать куда писать.
И да, если процессор может адресовать какую-либо память, то она именно что пересекается с адресным пространством процессора, иначе это должны быть специальные инструкции для специальной памяти. Могу предположить, что речь идёт о страничной адресации и всяких смещениях, которые вроде как дают память с нуля, но лежит она где угодно. Опять же не вижу особых преимуществ и эта память всё равно адресуется и о ней надо знать, что бы случайно не заюзать.
По поводу даты, тут вообще шикарная история, на самом деле достаточно всё того же счётчика тактов и хранение в виде строки, это полная лажа, от которой одни проблемы, не говоря уже о том, что реально в таком формате время нужно только на выводе, и это операция, которая вообще не требует оптимизаций, поэтому делать "предрасчёт" для дат и мучиться потмо с вычислениями... Но все именно этим и занимаются, почему? Потому что качество тактовых генераторов не достаточно, что бы отсчитывать время, там уже в сутки плывёт всё на секунды, поэтому все имеют гемморой и пишут время в некомпьютерном формате и счтитают в нём же.
Я не предлагал конкретный способ хранения даты. Я только предложил механизм, как это можно реализовать, а формат может быть любой.
Да не может быть формат любым, компьютеры - это не люди, два раза один и тот же час за сутки, это: дважды запущенное регламентное задание, которое не должно пересекаться само с собой и оно уходит в зависон, а подведение часов на одну секунду (это тоже реально практикуется, поскольку в сутках не 24 часа) и в результате, промежуток времени не меньше 1-2секунд превращается в НОЛЬ и прога уходит в синий экран.. таких фишек море. Люди к этому привыкли, а компьютеру это ни к чему, ведь есть реальная возможность учитывать время с точностью до такта и в периоде: миллоны лет.
на самом деле достаточно всё того же счётчика тактов
Не достаточно.
64 бита это: 18446744073709551616. Это 9749040289,2512005411804498562489 лет из расчёта 365 дней в году. Для процессора на 10ГГц это будет всего лишь 974 года, но как 8 битные процессоры работали с World, так и тут можно взять всего лишь два слова и получиться 18-что-то-ахриненно-там(первое число)*умноженное на примерно тысячу лет, этого хватит даже для историков. Учитывая проблему двухтысячного года, даже 64битный ПОТАКТОВЫЙ вариант имеет преимущество, над традиционным исчислением. И да, тактовую частоту, можно привести к стандарту, всё равно в реале используются множители. Но! Как я уже говорил, проблема лежит несколько в другой плоскости.
Счётчик тактов отсчитывает количество пройденных тактов с момента запуска компьютера и после каждой перезагрузки сбрасывается.
Он имеет ограниченный размер.
Как я УЖЕ говорил, для современных размерностей: уже достаточно!
Ну конечно, если вы имели ввиду то, чтобы его не сбрасывать никогда и сделать достаточно большим для хранении большого количество тактов, которого хватит на много веков, то может тогда и достаточно.
Я думаю, что лучше дату не хранить таким способом.
А я думаю, что лучше дату хранить именно таким способом, а для людей при выводе - пересчитывать.
и хранение в виде строки
В виде строки хранить глупо, другое дело хранить в числах.
Просто отошлю вас к стандартам SQL https://technet.microsoft.com/ru-ru/library/ms187928%28v=sql.105%29.aspx
Не знаю как это назвать, но это именно та ситуация, которая практикуется и в остальных языках (локаль приходится тоже учитывать), а тут - общепризнаная система для хранения данных (база), своего рода - квинтэссенция.
Кстати, Эксель, вполне себе в числах хранит даты, про тонны гневных писем в его адрес можете поискать самостоятельно, но я думаю, каждый имеет подобный опыт и даже интернет тут не нужен.
Если вам сложно разобраться в написанном, то просто пропустите этот пункт и не надо догадок по тому, чего не поняли.
Нет там никаких функций по блочной работе с памятью.
Нет, так - нет, но написанно было заумно, сами перечитайте.
RE: Оптимизация архитектуры - Added by VaalKIA over 10 years ago
Yaisis wrote:
VaalKIA wrote:
Про 30 раз в скорости, и замену деления: умножением со сдвигом - это просто смешно (ну можно же то же самое делать аппартно, если есть просчёты в архитектуре, то при чём здесь это?).
Не то число написал, примерно в 10 хотел написать, ошибся.
Вывод делался из того, что у Интела инструкция умножения выполняется за 3 такта, а инструкция деления примерно за 40, т.е. 40/3 = 13.33 раза.Потом идёт бла-бла-бла, 2 раза 128 штук...
Я же написал, что "от балды" -- это был просто пример, а реально есть ли эффективность или нет -- это надо оценивать.
Я никогда не говорил, что сразу надо что-то урезать там.
Я прост предполагаю, что 40 тактов не потому что инструкция сложная (не сильно сложней умножения), а потому что нет на неё спроса, по историческим причинам.
Прочтите вот это: http://habrahabr.ru/company/intel/blog/158223/ (жизнь в эпоху тёмного кремния. В кратце, при переходе на более тонкие нормы, заполняют много места "мусорными" транзисторами, ну а можно было бы схемой деления)
Если бы можно было бы, то заполнили.
А так же можно было бы дополнительными клетками без схемы деления.
Именно поэтому RISC архитектуры работают на больших частотах, чем CISC на том же технологическом процессе: в RISC блоки не зависимы, в CISC нельзя сильно разнести или "размазать" схему, какой-нибудь масштабной инстркуции. То же касается и всяких наворотов архитектуры x86, где помимо RISC ядер есть "целый искуственный интеллект" (цитирую себя же), который уже не размазывается и не ложится так просто на другие топонормы. Соответственно - это тупиковый путь.
Но при этом, почему-то ввели MMX, что бы не терять на декодировании инструкций и сразу делать умножение со сложением, а не выкинули деление, не?
Вы примеры не в тему приводите.
Узнайте для чего вводят SIMD команды и поймёте для чего ввели MMX.
Мультимедиа eXtension ввели для того что бы убить CISC процессоры и подтянуть 3D графику, с которой процы, тягаться всё равно не смогли. И основной рекламной фишкой, как мне помниться было именно: сложение с умножением, про всякие MMX2, 3DNow, 3DNow+ и прочее я уже не помню - не следил.
Ситуация с MMX никак не относится к моему примеру про матричные преобразования.
И в Интеле не так много вычислительных устройств, чтобы выкидывать деление, а вот если брать в пример графические карты, в которых под 4000 шейдерных процессоров, то там выкидывают деление, чтобы реализовать столько процессоров.
Не аргументированно. Не вижу причин, почему нельзя выкинут деление из Интела, кроме совместимости, в угоду которой инструкцию как раз и оставили, но не стали оптимизировать. Де факто, Интел это Risc процессор и в транзисторах разницы вообще нет, просто микропрограма стала чуть больше, за счёт микрокода, реализующего деление, а дополнительных ухищрений, требующих "аппаратных усилий" никто не делал - незачем.
Возьмём в пример старую видеокарту АМД ещё со VLIW-архитектурой, в которой команда состояла из 5 инструкций и только 5-я могла выполнять деление.
В современных видеокартах не знаю, как с этим делом.
К сожалению про VLIW в видеокартах вообще не слышал, я больше по универсальным процессорам. Но постараюсь почитать, даже не думал, что там нужно нечто подобное, в таких узкоспецилизированных (видимо - кода-то) железках.
Конечно хотелось бы иметь полноценные клетки, но в данном случае надо смотреть реальности в глаза и принимать соответствующие решения, которые в целом могут улучшить процессор.
Или - ухудшить.
Только улучшить, потому что урезаться всё будет только в том случае, если это принесёт пользу, иначе всё останется так, как есть.
Я не зря каждый раз пишу, что прежде чем что-то делать, надо сначала произвести оценку и узнать целесообразность внесения таких изменений.
Э - нет, сам красноречивый пример Интела с его x86 архитектурой, да и Итаниумом до кучи, говорит нам, что "гладко было на бумаге, да забыли про овраги". Так что имеет смысл не трогать основополагающие вещи, такие как ISA, в угоду сомнительным оптимизациям.
Чем меньше схема(клетка) занимает, тем больше схем(клеток) они смогут поместить в кристалл.
Это слишком упрощённо, что бы принимать это во внимание.
Посмотрите на шейдерные процессоры в видеокарте и посмотрите также, сколько их поместилось в данном процессоре. Их разработчики это всё приняли во внимание.
Точно также, как и последний Intel Xeon Phy -- он тоже урезан по сравнению с обычными десктопными процессорами и благодаря этому вмещает в себя 72 ядра, но он также будет в варианте обычного CPU. И насколько я знаю, в нём нет даже MMX-а, который вы привели выше, там только AVX оставили.
В чём-то вы правы, но мои наблюдения, которые коррелируют с многочисленными отзывами, во многом говорят о спорности такой интерпритации, проще говоря - меньшее количество ядер старых архитектур уделыают более многочисленные новые, да нам все твердят, что это "на вырост" и в будущем оно даст профит, но правда теряется в новых топонормах, то есть уже сравнивать не с чем. А по Интеловским процессорам (они очень резко изменили тактике упрощения процессора, как только даже их более тонкий техпроцесс стал сливать и АМД пошли на расхват, где-то в районе К7) и по Амд процессорам (которые так же решили упростить и попали в ту же историю, сразу же вслед за Интел (до сегодняшнего момента, надесь, Зен что-то исправит)) и даже по Арм процам (пример Apple, которые сделали более производительные но менее ядерные процы). Ну а про GPU я толко вижу, что прозводители идут тем же путём, стараясь сбалансировать и сделать универсальные, а не порезанные блоки, одна история с GeForce, где сэкономили на кеше памяти чего стоит, да и AMD туда же тянется и в новых картах, вроде как не три чего-то там на два блока, а по два в каждом и это, типа - круто. В общем, пример - ни о чём.
А зачем оптимизировать инструкцию, которую заменяют умножением со сдвигом? скажите спасибо, что её вообще не выкинули, ради совместимости. Как говорится: нет спросу, нет и завозу.
Тут я не понял о чём вы.
Вы хоть бы пример привели, что за инструкция такая ?
Может вы имели ввиду то, что иногда умножение или деление на число кратное двум заменяют сдвигом ?
На самом деле, мы получаем просто двоичные дроби, которыми можно выразить почти тоже, что и десятеричными, то есть, с небольшими доработками это заменяет любое деление. Если не очень понятно, то поясню: сдвиг, это деление на число кратное двойке, то есть, от деления там никуда не деться, но действия так разбиваются, что бы вместо деления на любое число, было умножение на какое-то число + деление на число кратное двум (а это уже просто сдвиг и можно делать за один такт). Например, в десятичной системе надо поделить 70 на 25, заменяем умножением на 4 и делением (сдвигом) на 100, итого 70*4=280, сдвигаем два разряда = 2,8. На практике, это означает что деление можно заменить умножением + 1 такт на сдвиг, но это всё упрощённо.
Ещё полезней, когда программист делит задачи по ядрам, а потом выясняется что все ядра отсрелялись и ждут последного, который гипер и у которого скорость в 10 раз ниже.
Такого не может быть. Процессоры не так функционируют.
Не может одна задача быть нагружена на виртуальное ядро и при этом чтобы остальные простаивали, т.к. виртуальные ядра используются тогда, когда все реальные заняты. Если в системе в сумме 8 ядер и 4 из них виртуальные, то при загрузке всего 4 потоков они всегда будут нагружать реальные ядра, а не виртуальные. Виртуальные нагружают только при количестве потоков большем, чем количество реальных ядер.
Любой поток на виртуальном ядре становится потоком на реальном ядре при освобождении реального ядра. Даже всё намного проще, но долго объяснять.
Вы описываете как работает Операционная Система, её менеджемент - не бесплатен, на переключение задач, Виндовс, тратит несколько ТЫСЯЧ тактов (зато он выберет правильные ядра, возможно даже поймёт что есть сдвоенные на одном кристалле и они работают быстрей в связке, чем третье ядро на кристалле с отключённым четвёртым). Да, при гигагерцах, это уже незначительно, но то, почему ОС делаться на ОСРВ и просто ОС, думаю - стало понятно, про то, что при этом идут лесом кеши и прочие вещи, которые ещё косвенно добавляют сотни тактов уже не имеет смысла говорить.
Нет, на практике, действительно, выгода - есть, но только надо учитывать, что есть такая вещь как ОС, которая жрёт просто тонну ресурсов, и её же обеспечение правильной работы треадинга на этом фоне просто теряется. Если же рассматривать в чистом виде, то лучше бы они простаивали, потому что не бывает бесплатного сыра и замедляется работа основного ядра во время работы гипертреадинга и тепловыделение увеличивается, и кеш дербанится и есть ещё куча нюансов, проще было бы ускорить основое ядро, вместо всей этой вумной обвязки (которая больше, чем "простаивающие" транзисторы). Но что это!? Оказывается архитектура x86 это такой монстр, что там, практически уже встроен искуственный интеллект, так что гипер-треадинг мы полчили почти бесплатно, но стоит ли повторять этот подвиг в нормальном проце.. - сомневаюсь. Тут как раз тот случай, когда нет худа, без добра. уж очень много они навертели, что бы вымученную архитектуру ускорить, но это же их и погубит, потому что в сравнении с нормальными архитектурами они просто - монстр, где всё надо выкинуть, а остальное - переделать (и АРМ c MIPS, наконец-таки стали популярны и скоро эта тема будет закрыта, особенно в свете всё большей кроссплатформенности ПО).
Такого бреда ещё не читал нигде.
Но скажу, что технология аналогичная гипер-треадингу полезна абсолютно для любого процессора. И для АРМ-ов и для МИПС-ов. И для Эльбрусов. И для Мультиклета, если они реализуют многопоточность. Только я думаю, что в Мультиклете она может появиться сама собой, без её умышленного создания.
Полезна она потому, что она старается заполнить работой по-максимуму имеющиеся ресурсы процессора. Без разницы сколько вы там ядер воткнуть сможете, гипер-треадин он повышает КПД каждого ядра и при этом занимает меньше места на кристалле, чем размещение дополнительных ядер, т.е. вы можете воткнуть в кристалл ядер под завязку так, что больше ядер у вас уже никак не влезет, но гипер-треадинг-то ещё влезет, а с ним КПД процессора будет выше и процессор будет производительней, чем без него.
Я не буду оспаривать, что на x86 платформе Гипер-Треадинг даёт реальное преимущество, хотя по моим наблюдениям никаих двух ядер на 4 там нет и в помине, а вот работа основных немного замедляется (ну не магически же данные в неиспользуемые блоки ядер попадают, значит как минимум портится кеш и возрастают задержки декодирования и конвееров, а в некоторых случаях это может быть замедление в разы
Например¶
Show HideВпервые, технология появилась на процессорах Pentium 4, но большого прироста производительности не получилось, так как сам процессор не обладал высокой вычислительной мощностью. Прирост составлял в лучшем случае 15-20%, да и во многих задачах процессор работал значительно медленнее чем без HT.
Замедление работы процессора из-за технологии Hyper Threading, происходит если:
Недостаточно кэша для всех данный и он циклически перезагружается, тормозя работу процессора.
Данные не могут быть правильно обработаны блоком предсказания ветвления. Происходит в основном из-за отсутствия оптимизации под определённое ПО или поддержки со стороны операционной системы.
Также может происходить из-за зависимости данных, когда к примеру, первый поток требует немедленных данных со второго, а они ещё не готовы, либо стоят на очереди в другой поток. Либо циклическим данным требуются определённые блоки для быстрой обработки, а они нагружаются другими данными. Вариаций зависимости данных может быть много.
Если ядро и так сильно нагружено, а «недостаточно умный» модуль предсказания ветвлений всё равно посылает данные, которые тормозят работу процессора (актуально для Pentium 4). 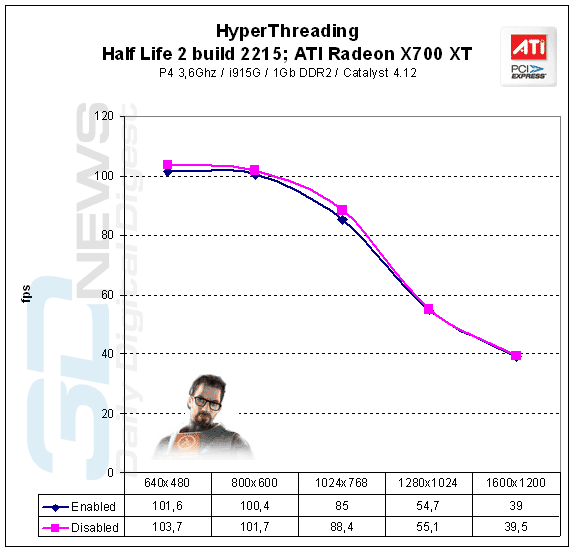



Причём максимум производительности HT фиксируют на двух ядрах, на четырёх она даёт даже меньше чем на двух, то есть, мало того, что она очень неоднозначна, так ещё и плохо масштабируется, ну о-о-очень перспективная технология. Нет ни одной материнской платы, на которой бы нельзя было отключить HT и конкуренты даже не думали перенимать эту технологию, хотя SSE вполне себе пошла по рукам. Ну и после очень плохого старта Интел была вынуждена произвести ребрендинг переименовав HT в SMT, что бы хотя бы не гнобили.
Справедливости ради, есть и положительный результат, возьмём базы данных, тут вообще скорость проца не важна, главное вовремя подобрать данные от очень медленного устройства и тут же дать ему новую комманду, дальше - ждать(видно, что задача масштабируется хорошо, коээфицент 1.8 от количества ядер), процессор E7-4870, вот результат (процентов 7, я думаю там есть, а обвязка HT есть в каждом ядре):
Про Бред, согласитесь, теперь звучит очень двусмысленно.
). Но вот "полезна абсолютно любому процу" это просто промытые маркитенгом мозги. Мой основной посыл: слишком сложна схема, реализующая поверх RISC архитектуру x86, все оптимизации, которые там приминенны, просто - монструозны, и на их фоне добавление нескольких чистых конвееров, дало бы несравненно больший эффект (причём не в некоторых, а во всех случаях, что кардинально меняет картину) и заняло гораздо меньше транзисторов, проблемма только в том, что x86 ISA настолько плохо параллелится, что не ложится он на несколько конвееров и приходится заниматься извратом, а добавление новых ядер автоматически добавляет обвязку извратов. В итоге - порочный круг, который АРМ уже рвёт в клочья, и x86 вымрет как динозавр. Соответственно, говорить, что смотрите, есть чудо схема в хрен знает сколько транзисторов, нифига не параллелящихся, которая почти забесплатно делает гипер-треадинг, просто возьмите и гипертреадинг прикрутите ещё куда-нибудь... ну, придётся как минимум, реализовать почти ту же обвязку, и в количественном отношении она будет измеряться в нормальных ядрах, сответственно она не даст НИ-ЧЕ-ГО, кроме тормоза, потому что является неким подобием CISC надстройки, который нифига не масштабируется, а вот добавление чистрых ядер в данном случае даёт очень много, потому что никакой обвязки не требует, ведь мы уже нормальный RISC имеем ввиду.
Современная же x86 от CISC-архитектуры оставила только набор инструкций и на первом этапе CISC команды преобразуются в RISC команды и выполняются внутри на RISC-ядре.
Почти. Сама по себе x86 архитектура (ISA) на RISC ложится плохо, поэтому её тянут вверх извращённым способом, и поэтому же она проигрывает, и програет чисто RISC процессорам.
Я не предлагал делать мегакоманд, а эффективная нагрузка вычислительных блоков присуща любой современной архитектуре и при этом к VLIW большинство из них не имеет отношения.
Как я уже упоминал о "Тёмном Кремнии" не всегда целесообразно стремиться к полностью загруженным блокам, на физическом, а не логическом уровне и есть много неочевидных нюансов. Это примерно как машина, вроде бы пашет хорошо, давайте заменим двигатель на более мощный и загрузим на 100% все блоки, тут же начнут сыпаться подвеска и тормоза и т.д., в итоге заменяются блоки всей машины на более мощные, не выдерживающие такой нагрузки, а скорости такой всё равно не повзволяет достичь аэродинамика. Так же и тут, ну перегревается один транзистор, но быстро остывает распределяя тепло на соседние, давайте загрузим его на 100 процентов и соседние тоже и будем отключать весь блок из-за перегрева или снизим частоту, потому что кристал уже не тянет такое энергопотребление и соответственно - выделение в этом блоке, да итактовый генератор проседает и его не хватает на другие блоки.
Да и не такая идеология у VLIW, а другая -- чтобы не делать суперскаляр нужно распараллелить инструкции на стадии компиляции и объединить их в широкое командное слово(VLIW), инструкции из которого можно выполнить параллельно.
Или сменить парадигму и отвязать комманды от последовательного исполнения, и эта парадигма - Мультиклет, с его исполнением по готовности и параграфами, которые на голову выше VLIW слова.
Таким образом параллельно можно выполнять больше инструкций, т.к. аппаратно почти невозможно создать аналогичный по эффективности блок суперскаляра. Плюс идёт экономия кучи транзисторов, так как многое выполняется на стадии компиляции, а не выполнения.
Можно выполнить больше инструкций, или - меньше (относительно, особенно если частота упала а количество блоков возросло), если сменилась архитектура и старый скомпилированный код не загружает новоархитектурные блоки, ещё хуже, если какой-то блок преобразовали "старая" комманда теперь эмулируется (она-то прежней осталась, а вот сочетается теперь по другому), да ещё и по прерыванию. Как я уже говорил, эффективность у VLIW действительно повышается, но ценой привязки к конкретной архитектуре, а это, как минимум - не современно, а как максимум - контрпродуктивно.
Выше я ответил, с Эльбрусом, к сожалению, не знаком, надесь наши что-то придумали. А вот, про Трансмету вы почитайте, что особенно актуально, в силу того, что она не взлетела, да и Итаниум всеми силами тянет такой гигант, но результат, для таких услилий - весьма посредственный, а когда-то они x86 закрывали, говорили-то что 64 бита - не будет, мы вам Итаниум сделали - это будуее, не припомните? Они бы уже по миру пошли, если бы это был не блеф.
Недостатки же Трансметы и Интела происходят из-за неправильной реализации -- они могли сделать также, как в Эльбрусе, но не сделали.
Так это - как? Поясните отличие.
Повторю ещё раз, что моё предложение никак не относиться к VLIW-архитектуре.
Предложение - нет, описание - да, но просто опустим это.
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
Я прост предполагаю, что 40 тактов не потому что инструкция сложная (не сильно сложней умножения), а потому что нет на неё спроса, по историческим причинам.
Её не смогли сильнее оптимизировать. И если я не ошибаюсь, то там алгоритм Бабаяна используется, лучше которого не придумали.
Инструкция деления намного сложнее умножения.
Если бы её могли сделать быстрее, то сделали бы, т.к. она тоже очень важна.
Мультимедиа eXtension ввели для того что бы убить CISC процессоры...
Не для этого его ввели, т.к. к этому оно не имеет отношения.
Такие расширения могут быть как в CISC архитектуре, так и в RISC и служат они для ускорения вычислений.
Они прекрасно вписываются в концепцию CISC-архитектуры.
Де факто, Интел это Risc процессор и в транзисторах разницы вообще нет, просто микропрограма стала чуть больше, за счёт микрокода, реализующего деление, а дополнительных ухищрений, требующих "аппаратных усилий" никто не делал - незачем.
Посмотрите на код x86, разве он является RISC кодом ?
Конечно нет, он CISC и накладывает соответствующие ограничения в виде того, что нельзя параллельно считывать инструкции, т.к. они имеют разную длину и поэтому нельзя определить адрес следующей инструкции пока не считается предыдущая.
Совсеремнные процессоры Интел внутри имеют RISC-архитектуру, но формат x86 кода-то RISC, поэтому есть там дополнительные транзисторы на преобразование кода CISC в код RISC и на это уходит дополнительный этап конвейера. В полностью RISC процессорах нет такого лишнего преобразования.
К сожалению про VLIW в видеокартах вообще не слышал, я больше по универсальным процессорам.
Я и привёл в пример видеокарту лишь потому, что там полно шейдерных процессоров и чтобы столько уместить, они пожертвовали некоторыми инструкциями.
Если в процессоре мало вычислительных блоков, то и нет особого смысла урезать их(я так думаю). Мультиклет же я рассматриваю в будущем, как конкурент по вычислениям видеокартам, но конечно не знаю, что из него получится.
Так же в современных видеокартах вроде используется SIMD, а не VLIW.
Э - нет, сам красноречивый пример Интела с его x86 архитектурой, да и Итаниумом до кучи, говорит нам, что "гладко было на бумаге, да забыли про овраги". Так что имеет смысл не трогать основополагающие вещи, такие как ISA, в угоду сомнительным оптимизациям.
Ну конечно, не всегда в теории удаётся всё предсказать правильно, но пока не попробуешь, истину не узнаешь.
Если же теория предсказывает хороший результат, то попробовать стоит, а откатиться всегда можно.
...В общем, пример - ни о чём.
Если у АМД, Интел, Нвидиа, были сложные ядра, потом они упростили их, добавили много и получился результат хуже, то это автоматически не означает, что данный подход плохой, возможно везде плохая реализация. Нельзя чужие неудачи приводить в качестве примеров.
Много простых ядер даёт преимущество на задачах, которые отлично распараллеливаются и в таких ситуациях производительность множества упрощённых ядер обычно выше, чем мало ядер, но на большой частоте. Как пример -- все видеокарты, где ядер полно и все они упрощённые, но на задачах, которые отлично распараллеливаются, они уделают любой CPU по вычислительной мощности.
(конечно, кроме самого последнего Intel Xeon Phi, который является уже CPU и имеет 72 ядра, которые могут противостоять видеокартам)
Если не очень понятно, то поясню: сдвиг, это деление на число кратное двойке, то есть, от деления там никуда не деться...
Сдвиг -- это ни разу не деление, а это именно сдвиг. А ускорение деление и умножение на степень двойки можно ускорить благодаря сдвигам -- это из-за особенностей двоичной системы.
Приведу пример:
Число 1 в двоичной системы -- это 00000001
Число 2 в двоичной системе -- это 00000010
Т.е. видно, что если просто 1 бит сдвинуть влево, то происходит умножение на 2, а если сдвинуть вправо, то происходит деление на 2, при этом не задействуются операции умножения и деления, просто так устроена двоичная система, что это происходит само-собой при сдвиге.
Операция сдвига выполняется за 1 такт, умножение -- за 3, а деление примерно за 40. И поэтому выгодно заменять сдвигами там, где это возможно.
Если бы у нас был троичный компьютер, то там сдвиги уже выполняли бы умножение и деление на 3, а не на 2.
Вы описываете как работает Операционная Система, её менеджемент - не бесплатен, на переключение задач, Виндовс, тратит несколько ТЫСЯЧ тактов (зато он выберет правильные ядра, возможно даже поймёт что есть сдвоенные на одном кристалле и они работают быстрей в связке, чем третье ядро на кристалле с отключённым четвёртым). Да, при гигагерцах, это уже незначительно, но то, почему ОС делаться на ОСРВ и просто ОС, думаю - стало понятно, про то, что при этом идут лесом кеши и прочие вещи, которые ещё косвенно добавляют сотни тактов уже не имеет смысла говорить.
Я описал именно гипер-треадинг и к работе ОС он не имеет никакого отношения. ОС может загрузить процессор потоками, но если в процессоре 4 реальных ядра и 4 виртуальных, то при сумарном количестве потоков равном 4, виртуальные ядра никогда не будут задействованы. Это даже умышлено запрограммировать нельзя. Если у вас было 5 потоков и один из них на виртуальном ядре, то это не означает, что какой-то из 5 потоков всегда на виртуальном ядре, на самом деле они могут все по-очереди попадать на виртуальное, но если один поток прикрыть, то все оставшиеся 4 сразу же будут вычисляться на реальных ядрах и ОС этим не управляет. ОС может только узнать, что в системе присутствует столько-то реальных ядер и столько-то виртуальных, но она не может заставить работать только одни виртуальные, т.к. это всё на аппаратном уровне.
Теоретически конечно ОС может поставить наивысший приоритет потока и тогда он всегда должен попадать на реальное ядро.
И вообще виртуальные ядра -- это вымысел. В процессоре есть указатели на адрес инструкции для каждого потока. Поэтому адресу всегда берутся инструкции реальными ядрами, но если у реального ядра есть простаивающие блоки, то они их заполняются инструкциями из других потоков, создавая видимость виртуальных ядер. Итого в системе есть 4 ядра, но 8 потоков. Эти 4 ядра берут иснтрукции из всех 8 потоков и пытаются по-максимуму заполнить свои вычислительные блоки.
Давайте рассмотрим пример, допустим у нас одно ядро с гипер-треадингом, т.е. ОС видит его как 2 двух-ядерный процессор и предоставляет ему в нагрузку 2 потока.
В реальности процессор будет брать инструкции из двух потоков и если в одном например идут целочисленные операции, то значит блок FPU может простаивать, но если оказалось, что во втором потоке идут вещественные операции, то одно ядро может сразу начать выполнять инструкции из двух потоков -- одним оно будет заполнять целочисленные блоки, а другим -- вещественные. Заранее никто не знает, какой из потоков является реальным, а какой виртуальным, т.к. они равны при равных приоритетах выполнения, выставленных ОС. Если же мы любой из этих двух потоков прикроем, то на ядро будет попадать оставшийся один поток и он будет загружать ядро по-максимуму, как сможет, при этом будут простаивающие блоки, которые просто нечем будет заполнить. Так вот гипер-треадинг -- это механизм заполнения вычислениями этих простаивающих блоков. Если количество потоков равно количеству ядер, то никакой гипер-треадинг и не работает в данный момент.
Т.е. чтобы гипер-треадинг работал, надо на ядро подавать как минимум 2 потока и тогда это одно ядро берёт инструкции сразу из двух потоков и заполняет свои вычислительные блоки по-возможности.
Я не буду оспаривать, что на x86 платформе Гипер-Треадинг даёт реальное преимущество, хотя по моим наблюдениям никаих двух ядер на 4 там нет и в помине, а вот работа основных немного замедляется (ну не магически же данные в неиспользуемые блоки ядер попадают, значит как минимум портится кеш и возрастают задержки декодирования и конвееров, а в некоторых случаях это может быть замедление в разы
И привели в пример тест из игры.
Если программа плохо распараллелена, то естественно она будет показывать плохие результаты.
Я же говорил про свою отлично-распараллеленую программу, которую написал сам и она показала преимущества от гипертреадинга в виде двух дополнительных ядер.
Так же я её тестировал только на своём процессоре, поэтому не могу утверждать, что на других моделях будет такое же преимущество.
Игры параллелятся хуже, чем программы выполняющие какие-то расчёты над большим массивом данных.
Если программу хорошо распараллелить, то будет эффект от гипер-треадинга -- в примерах ваших тестов распараллеливание плохое.
Но вот "полезна абсолютно любому процу" это просто промытые маркитенгом мозги.
Это не промытие мозгов и не маркетинг. Это мой вывод и чтобы его понять, надо узнать, как работает внутри гипертреадинг.
Давайте я вам приведу ещё раз пример:
Допустим у нас одно ядро с гипертреадингом и мы загрузили его двумя процессами. В одном идёт целочисленный расчёт, а в другом вещественный.
В ядре же присутствуют как целочисленные блоки, так и вещественные. И получается, что если мы загрузим ядро одним потоком, то будет занята расчётами только половина блоков процессора, а вторая половина будет простаивать -- разве это хорошо, что вторая часть простаивает ?
В данном примере процессор заполнит вычислениями и вторую часть процессор из другого потока и по производительности будет вести себя, как двух-ядерный процессор, но размер ядра на кристале будет примерно равен одноядерному.
Теперь давай представим ваше предложение -- заместо гипер-треадинга добавить второе ядро, т.е. количество транзисторов на кристалле удваивает и в результате эти два потока могут выполняться на двух ядрах, показывая туже производительность, но если посмотреть повнимательней, то у одного ядра будут заполнены вычислениями целочисленные блоки, а у другого -- вещественные и также у одного будут простаивать вещественные блоки, а у другого целочисленные, т.е. в сумме будет простаивать половина вычислительных блоков процессора.
Так почему их не заполнить вычислениями ?
А технология, которая заполняет их вычислениями, называется гипер-треадинг и сколько бы вы ядер не добавляли в процессор, всегда в нём будут простаивающие блоки, но чем больше таких блоков, тем КПД процессора ниже и больше транзисторов, работающих в пустую.
В результате с помощью гипер-треадинга можно незначительно усложнить ядро, но сильно поднять КПД процессора и в результате ядро с гипертреадингом по максимальной производительности будет всегда лучше, чем ядро без него, а загрузка этих дополнительных вычислительных ресурсво зависит только от задачи и программиста.
И это незначительное усложнение ядра обходиться дешевле, чем добавление дополнительных ядер.
Мой основной посыл: слишком сложна схема, реализующая поверх RISC архитектуру x86
Я не защищаю x86, я защищаю гипертреадинг. x86 мне и самому не нравится.
А гипер-треадинг есть не только в x86, а например в процессорах полностью RISC процессоре IBM POWER -- посмотрите сколько там потоков может выполнять одно ядро.
Просто там технология, возможно, по-другому называется, но суть её та же.
Так же свой гипер-треадинг есть в видеокартах АМД, про Нвидиовские не знаю.
Он заставляет вычислительные блоки процессора больше работать, загружая их инструкциями из других потоков, а не ждать, когда в них придут инструкции из конкретного текущего потока.
а вот добавление чистрых ядер в данном случае даёт очень много
Я вам уже привёл пример с добавлением чистых ядер -- тоже количество чистых ядер, но с гипер-треадингом может дать на 50% больше. При этом ядро с гипертреадингом и без него по количеству транзисторов занимает примерно одинаковый объем.
Или сменить парадигму и отвязать комманды от последовательного исполнения, и эта парадигма - Мультиклет, с его исполнением по готовности и параграфами, которые на голову выше VLIW слова.
Я написал, что такое VLIW. Подход Мультиклета мне тоже нравится больше.
Как я уже говорил, эффективность у VLIW действительно повышается, но ценой привязки к конкретной архитектуре, а это, как минимум - не современно, а как максимум - контрпродуктивно.
Как я уже говорил -- нету там привязки. Всё зависит от реализации.
Главное хороший компилятор, программист и промежуточный код, который может подстраиваться под архитектуру.
Хороший программист напишет наилучший алгоритм под данную задачу и напишет его так, чтобы у компилятора не было проблем с его распараллеливанием.
С помощью промежуточного байткода его программу можно перенести на любую архитектуру, а этот промежуточный байткод должен хорошо подогнать компилятор самой архитектуры.
В Интеле могли бы создать вместо суперскаляра VLIW процессор с шириной VLIW-слова равной 5 инструкций и вместо того, чтобы в реальном времени работы алгоритма какой-то схемотехникой распараллеливать однопоточный код, могли бы по тому же самому алгоритму распараллелить его на стадии компиляции. При этом и там и там максимум параллельно выполняемых инструкций за такт равно 5, а минимум - 1. Без супер скаляра может они бы смогли даже выше частоту поднять, так как нет лишней схемотехники по распараллеливанию. Плюс на стадии компиляции можно получить более оптимальный код, т.к. суперскаляр имеет алгоритмы хуже, т.к. ограничен бюджетом транзисторов и энергопотреблением. Компилятор же ничем не ограничен.
Так это - как? Поясните отличие.
На сайте МЦСТ есть статья Бабаяна, где он говорит о различиях Интел Итаниум и Эльбрус 2000.
Современные Эльбрусы -- наследники Эльбрус 2000.
Предложение - нет, описание - да, но просто опустим это.
Ни предложение, ни описание не относится к VLIW-у.
Что оно относится может заявлять только человек, который не знает, что такое VLIW, а VLIW -- это главным образом группировка команд в группу, из которой все команды можно выполнить параллельно. Группировка происходит на стадии компиляции и помечается особым способом. Эта пометка с группировкой называется широким командным словом(VLIW), от-сюда и название архитектуры. Обязательно, чтобы группировка выполнялась на стадии компиляции, иначе это уже будет не VLIW.
Сколько бы вы не выполняли параллельно команд в своей архитектуре, но если инструкции на выполнения подаются на в виде заранее подготовленных VLIW-слов, то это уже не VLIW-архитектура.
Для сравнения: Одно из предыдущих поколений видеокарт основывалось на VLIW-архитектуре и имело VLIW-слово шириной 5 команд -- код, состоящий из соответствующих VLIW-слов подготавливал заранее компилятор. В результате одно вычислительное устройство могло одновременно выполнить 5 инструкций. В процессорах Интел нет VLIW-слов и его код распространяется не в формате VLIW-слов, но одно ядро Интел может одновременно выполнить тоже примерно 5 инструкций за раз, а распараллеливание идёт уже за счёт суперскаляра. Но вы же не назовёте архитектуру Интела VLIW-архитектурой верно ? Тоже самое, что я предлагал для Мультиклета никаким боком не относится к VLIW, так как там нет заранее подготовленных VLIW-слов, а загрузка соответствующих блоков происходит на аппаратном уровне, что исключает VLIW-архитектура по своей логике.
Да и Мультиклет вы же тоже VLIW-ом не называете, хотя он параллельно может выполнять инструкции из кода, отсюда не понятно, где в моих предложениях вы увидели VLIW, когда его там не было.
(У меня получился тоже большой комментарий. Давайте стараться их делать поменьше.)
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
Мне интересно, что будет, если в Мультиклете в одном такте сразу несколько клеток будут модифицировать одну ячейку памяти ?
Т.е. например процессор реконфигурирован на 2 потока и так совпало, что в одном такте в обоих потоках идёт, например, прибавление какого-то числа к переменной x. Пусть например в первом потоке прибавляется 2, во втором 3, а x=1.
Как Мультиклет обработает данную ситуацию ?
Чему в результате будет равна переменная x ?
RE: Оптимизация архитектуры - Added by ak_multiclet over 10 years ago
Произойдёт то же самое, что и в обычной многопоточной системе: неопределённое поведение.
Аппаратура, разумеется, не сможет дать одновременный доступ к одному сегменту памяти, потоки пойдут туда по очереди (соответственно затянется выполнения инструкций доступа к памяти), но в каком порядке, предсказать нельзя.
Тут никаких откровений: мультиклеточная архитектура не отменяет необходимость соблюдения программистом правил техники безопасности, от мьютексов и критических секций отвертеться не получится.
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
ak_multiclet wrote:
Произойдёт то же самое, что и в обычной многопоточной системе: неопределённое поведение.
Аппаратура, разумеется, не сможет дать одновременный доступ к одному сегменту памяти, потоки пойдут туда по очереди (соответственно затянется выполнения инструкций доступа к памяти), но в каком порядке, предсказать нельзя.
Тут никаких откровений: мультиклеточная архитектура не отменяет необходимость соблюдения программистом правил техники безопасности, от мьютексов и критических секций отвертеться не получится.
Я так и предполагал, хотел предложить один из способов улучшения архитектуры, но потом понял, что он не подойдёт и удалил всё, что написал.
Там же получается, что все инструкции в примере итак независимы, а зависим только доступ к памяти.
потоки пойдут туда по очереди (соответственно затянется выполнения инструкций доступа к памяти), но в каком порядке, предсказать нельзя.
И так же, как я понимаю, что в приведённом мной примере нельзя гарантировать, что результат будет равен 6, хоть потоки и будут выполняться по-очереди. Так как два потока могут сначала считать значение x, равным 1, а потом один прибавит к нему 2, а второй прибавит 3.
В результате x будет равен либо 3, либо 4, либо 6(если второй поток каким-то образом считал результат после сохранения первого потока или наоборот).
RE: Оптимизация архитектуры - Added by ak_multiclet over 10 years ago
Да, всё верно, "прелести" параллелизма -- они такие. Ещё и при отладке отлавливаются плохо: по шагам идёшь -- всё хорошо, а в свободном прогоне внезапно всё валится.
Единственное, что было бы неплохо заиметь -- аппаратные блоки мьютексов (как это делает, например, Freescale) (как раз для синхронизации доступа к одновременно изменяемым данным).
Сейчас у нас для этого придётся целый алгоритм городить (см. "Алгоритм Петерсона" и "Алгоритм булочной"), т.к. атомарных операций "чтение-модификация-запись" или "тест-и-запись" у нас нет. Вообще, в многоядерных системах эта "атомарность" реализована... некрасиво, что-ли: на время выполнения подобных операций просто полностью блокируются межъядерные шины, чтобы никто другой в память (и кэши, ага) не влез.
RE: Оптимизация архитектуры - Added by VaalKIA over 10 years ago
А вот насколько я понимаю многоядерное программирование, то там всячески следует избегать глобальных переменных и разделяемых ячеек. То есть, если надо 1000 раз сделать вычисление функции и проссумировать результат, то надо не одну ячейку долбить результатами с разных ядер, а завести массив на 1000 ячеек, запустить времязатратные функции в параллель, как только они все отработали (без всяких конфликтов, заметьте), суммируем результаты, тоже на нескольких ядрах, типа дихотомии (и тут тоже ничего конкурентного не наблюдается). Вопрос тут стоит только как узнать что все функции отработали (не цикл же крутить, да и он в процессе опроса как раз будет создавать конфликты), а второй момент, это насколько у нас быстрый доступ к памяти (двухпортовая, кстати, там вместо 4 транзисторов 6, так что она относительно дешёвая и т.п.). Соответственно, в языках программирования есть такие вещи как MemoryBarrier, не знаю как это реализовано, но подразумеваю, что по прерыванию (про прерывания я уже говорил пару ласковых в разных темах) на любую запись в память, к примеру. Если это так, то это вообще не-Good, тут как раз нужны какие-то функции, скорее в блоке DMA, которые позволят сказать, что в каком-то блоке памяти все ячейки были перезаписаны, да ещё и без прерываний, то есть какая-то инструкция процессора должна тупо заснуть, до прямого сингнала от DMA (кстати, если условится, что каждая фукция ровно один раз туда пишет, то достаточно просто посчитать сколько раз была запись в определённый блок, даже вообще без контроля конкретных адресов. И тут мы постепенно приходим к атомарному неблокирующему инкременту, который вроде как аппаратная очередь и может быть обычной инструкцией проца просто с буфером размерностю в количество ядер и производительностью 1 сложение за такт), возможно это как-то можно сделать вашим механизмом "исполнение по готовности" и это ядро вообще будет лопатить другие данные без простоя.
Ну а по поводу всяких мьютексов и других красивых слов, следует начинать с того, что разделить на две части подход в к разеляемым данным:
Это пессимистичный, который предполагает, что данные в ячейке скорее всего уже изменились, так что имеет смысл всегда всё блокировать.
И оптимистичный, который предполагает, что данные скорее всего поменяться не успели, так что жарим дальше, ну а когда выясниться что всё-таки изменились, то откатим всё обратно, то есть транзакционный механизм.
А то как-то вы сразу со своими мьютексами встали на светлую сторону, а как же тёмная сторона силы? ;-)
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
ak_multiclet wrote:
Да, всё верно, "прелести" параллелизма -- они такие. Ещё и при отладке отлавливаются плохо: по шагам идёшь -- всё хорошо, а в свободном прогоне внезапно всё валится.
Единственное, что было бы неплохо заиметь -- аппаратные блоки мьютексов (как это делает, например, Freescale) (как раз для синхронизации доступа к одновременно изменяемым данным).
Сейчас у нас для этого придётся целый алгоритм городить (см. "Алгоритм Петерсона" и "Алгоритм булочной"), т.к. атомарных операций "чтение-модификация-запись" или "тест-и-запись" у нас нет. Вообще, в многоядерных системах эта "атомарность" реализована... некрасиво, что-ли: на время выполнения подобных операций просто полностью блокируются межъядерные шины, чтобы никто другой в память (и кэши, ага) не влез.
Ещё есть вот такая атомарная инструкция, которая выполняет сравнение и обмен:
cas(*a,b,c){
if(*a==b) { a=c; return true; }
return false;
}
,где разрядность типов a,b и c равна разрядности архитектуры.
Такая инструкция вроде во всех процессорах есть, а кто-то считает, что её одной достаточно, а остальные атомарные инструкции необязательны и могут быть не атомарны.
Можно было бы например сделать, чтобы при модификации памяти больший приоритет имели клетки с меньшим индексом, т.е. если одновременно изменяют память клетки 1 и 3, то тогда первой её изменит клетка 1, а второй клетка 3. В таком случае инструкции станут атомарны, но тут надо упорядочивание добавить по индексу клетки и только для одинаковых адресов.
Я не знаю, как у вас внутри там работает, поэтому может говорю, что-то не совместимое с вашей реализацией.
И так же я не уверен, что атомарность решит проблему, ведь у вас сначала происходит чтение из памяти в какой-то тег, потом выполняется алгоритм, а потом идёт запись обратно в память, но атомарность -- это же блокировка с момента чтения до конца записи, а если алгоритм большой, то тут может быть уже надо целый параграф или несколько параграфов блокировать, поэтому в таких ситуациях полезней специальная инструкция блокировки и разблокировки(lock и unlock).
Ну а если например представить, что у вас есть инструкции "add память, значение", которая прибавляет к "памяти" "значение" и на время этой операции блокирует адрес памяти, то тогда можно было бы писать такой код:
sum = 0;
foreach(i; parallel(0..l)) {
sum += a[i]*b[i];
}
И он бы распараллелился и правильно выполнялся.
Конечно такой код выглядит красивей и работать должен быстрей, чем с дополнительными инструкциями блокировки, но как я уже писал выше -- не везде подойдут атомарные операции, хотя конечно с помощью их можно было бы блокировать целые параграфы уже на уровне кода. Только у вас же вроде инструкции работают с тегами, а не с памятью и наверно атомарность в таком случае сложнее создать, т.к. в каждом потоке свой тег. Тогда выход тут -- это делать атомарную инструкцию по блокировки и разблокировки памяти. Может даже вышеназванная инструкция сравнение с обменом подошла бы для этой цели(только её надо подредактировать внутри):
sum = 0;
foreach(i; parallel(0..l)) {
с = a[i]*b[i];
do {
oldsum = sum;
newsum = sum + с;
}while(!cas(&sum,oldsum,newsum));
}
Этот код будет неправильно работать, если newsum будет равен 0(конечно можно было бы модифицировать инструкцию cas, чтобы она ещё изменяла и oldsum и тогда бы она подошла и для таких случаев). И так же мне не нравится, что в данном коде в цикле могут выполнятся лишние сложения, которые в результате не будут применены к sum, но на аппаратном уровне можно было бы инструкцию cas сделать например из двух инструкций и вторая инструкция была бы заместо третьего параметра и выполнялась бы она в случае совпадения первых двух. Тогда в качестве второй можно было бы подставить сложение. Конечно такая комбинация наверно сложна для Мультиклета, поэтому я тут просто размышляю и может быть натолкну на какие-нибудь мысли.
Единственное, что было бы неплохо заиметь -- аппаратные блоки мьютексов (как это делает, например, Freescale) (как раз для синхронизации доступа к одновременно изменяемым данным).
А может и это был бы неплохой выход из ситуации.
В любом случае вам что-то надо будет придумать, чтобы облегчить параллельное программирование и при этом, чтобы это работало эффективно.
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
VaalKIA wrote:
А вот насколько я понимаю многоядерное программирование, то там всячески следует избегать глобальных переменных и разделяемых ячеек. То есть, если надо 1000 раз сделать вычисление функции и проссумировать результат, то надо не одну ячейку долбить результатами с разных ядер, а завести массив на 1000 ячеек, запустить времязатратные функции в параллель, как только они все отработали (без всяких конфликтов, заметьте), суммируем результаты, тоже на нескольких ядрах, типа дихотомии (и тут тоже ничего конкурентного не наблюдается).
В данном случае такое программирование не удобно и потребляет больше памяти, да и не все алгоритмы для такого подходят. Конечно, если алгоритм подходит, то можно сделать и так.
Вот например приведу повторно код:
sum = 0;
foreach(i; 0..l) {
sum += a[i]*b[i];
}
Как вы описали -- надо сначала вычислить все произведения a[i]*b[i] и поместить их например в массив c[i], а потом в отдельном цикле проссуммировать эти значения, при этом лучше выполнить пиррамидальное суммирование, чтобы было быстрее. Вы уже представили, как усложнился код и как ухудшилась его читаемость ? Ну и кроме этого повысилось потребление памяти, т.к. мы в ней выделили ещё один массив c[i].
А теперь представьте, что в процессоре инструкция сложения атомарна, то тогда данный код можно распараллелить так:
sum = 0;
foreach(i; parallel(0..l)) {
sum += a[i]*b[i];
}
Смотрите какой красивый и легкочитаемый код, при этом нет выделения лишней памяти. Правда тут сложение всё-равно через очередь и пирамидальное сложение должно быть быстрее.
Вопрос тут стоит только как узнать что все функции отработали (не цикл же крутить, да и он в процессе опроса как раз будет создавать конфликты)
Можно запустить несколько потоков и все они прибавят одну переменную, естественно по-очереди(через блокировку или атомарную функцию), точно также по своему завершению они будут отнимать от данной переменной единицу. А в коде будет сравнение, если данная переменная равна нулю, то код идёт дальше, т.к. все потоки завершились, иначе будет ждать пока не 0.
Ещё можно было бы попробовать реализовать приостановку главного процесса, но каждый дочерний поток после вычитания 1 сравнивал бы данную переменную с 0 и если она равна нулю, то отключал бы "паузу" у главного потока, в таком случае цикл не нужен.
Ну а по поводу всяких мьютексов и других красивых слов, следует начинать с того, что разделить на две части подход в к разеляемым данным:
Это пессимистичный, который предполагает, что данные в ячейке скорее всего уже изменились, так что имеет смысл всегда всё блокировать.
И оптимистичный, который предполагает, что данные скорее всего поменяться не успели, так что жарим дальше, ну а когда выясниться что всё-таки изменились, то откатим всё обратно, то есть транзакционный механизм.А то как-то вы сразу со своими мьютексами встали на светлую сторону, а как же тёмная сторона силы? ;-)
И мьютексы эффективней этого, особенно эффективней транзакции, в которой выполняются расчёты, а потом оказывается, что всё было зря, тогда зачем тратили вычислительные ресурсы ?
Речь же шла не об определениях в реализациях соответствующих механизмов в базах данных, а о том, как это реализовать на самом низком уровне.
А пессимистичные и оптимистичные подходы -- это уже более высокий уровень, который реализуется на уровне кода.
RE: Оптимизация архитектуры - Added by ak_multiclet over 10 years ago
VaalKIA wrote:
А то как-то вы сразу со своими мьютексами встали на светлую сторону, а как же тёмная сторона силы? ;-)
Дык, я ж не спорю, что многопоточное/параллельное программирование -- вещь занятная и интересная.
Просто тов. Yaisis пропросил рассмотреть очень конкретный случай: потоки уже пошли в одну ячейку памяти. А мьютексы привёл лишь в качестве примера "средств индивидуальной защиты", обеспечивающих выполнение требований ТБ.
RE: Оптимизация архитектуры - Added by VaalKIA over 10 years ago
Как вы описали -- надо сначала вычислить все произведения a[i]*b[i] и поместить их например в массив c[i], а потом в отдельном цикле проссуммировать эти значения, при этом лучше выполнить пиррамидальное суммирование, чтобы было быстрее. Вы уже представили, как усложнился код и как ухудшилась его читаемость ?
Согласен, для легковесных вычислений, которые в функцию запихивать особого смысла нет, да и для сильно связанных данных описанный мной примитивный подход не годится. Значит нужны спец инструкции в большом количестве.
Вопрос тут стоит только как узнать что все функции отработали (не цикл же крутить, да и он в процессе опроса как раз будет создавать конфликты)
Можно запустить несколько потоков и все они прибавят одну переменную, естественно по-очереди(через блокировку или атомарную функцию), точно также по своему завершению они будут отнимать от данной переменной единицу. А в коде будет сравнение, если данная переменная равна нулю, то код идёт дальше, т.к. все потоки завершились, иначе будет ждать пока не 0.
Я уже написал, что для некоторых случаев вообще не нужны блокировки, поскольку порядок не важен, ну ведь полно же операций где от "перемены мест слагаемых сумма не изменяется", а важен только конечный результат. Соответственно, там нужна не блокировка, а буфер, тогда 4 ядра без всякого торможения одновременно "добавят" (поставят в очередь в буфер) в такой "аккумулятор" по числу и займутся своими делами, а его значение будет расти ещё 4 такта (ну это условно, там можно по разному сделать). Зачем тут блокировка? И заранее забегу вперёд, представьте, что ядер у нас несколько сотен, и мы их всех блокируем, то есть 500*N тактов длится блокировка (да функции уже давно всё вычислили тактов за 40, но ещё 400 будут ждать что бы об этом сообщить), нормально?
Ещё можно было бы попробовать реализовать приостановку главного процесса, но каждый дочерний поток после вычитания 1 сравнивал бы данную переменную с 0 и если она равна нулю, то отключал бы "паузу" у главного потока, в таком случае цикл не нужен.
Развёртка цикла проверки на множество ядер, это хорошая идея, но узкое место в виде конфликта тут никуда не исчезает. Наример, 1000 ядер получили задание, ровно через сколько-то тактов 300 из них завершили выполнение и пытаются таким образом сделать проверку.. пока они стоят в блоке остальные 700 тоже завершили задание и тоже стоят в блоке, в итоге они все стоят в блоке и тупо последовательно жарят эту несчастную ячейку.
Вот про приостановку процесса я как раз размышлял, но не представляю как это должно быть в железе без циклов и прерываний.
А то как-то вы сразу со своими мьютексами встали на светлую сторону, а как же тёмная сторона силы? ;-)
И мьютексы эффективней этого, особенно эффективней транзакции, в которой выполняются расчёты, а потом оказывается, что всё было зря, тогда зачем тратили вычислительные ресурсы ?
Речь же шла не об определениях в реализациях соответствующих механизмов в базах данных, а о том, как это реализовать на самом низком уровне.
А пессимистичные и оптимистичные подходы -- это уже более высокий уровень, который реализуется на уровне кода.
Не соглашусь, вы мыслите текущими десктопными (уже даже вчерашнего дня) реалиями. Когда у вас 4 ядра, мьютексы лучше чем транзакции и то весьма условно, когда у вас несколько сотен вычислительных ядер, вы рискуете всё время простоять в блокировках и скорость вычисления будет даже ниже чем на одном ядре, а вот транзакции прекрасно будут работать и с 10000 ядер, как раз решая проблему. Другой вопрос, что они тоже не решают весь спектр задач, и если данные очень изменчивы, то и транзакции повиснут в откатах, поэтому это два равноценных механизма, которые должны быть. По поводу низкоуровневости, посмотрите на тему транзакционной памяти, которую полностью реализуют в железе.
Про сотни ядер я не утрирую, такие процессоры уже есть, даже в быту видекарты именно такие. И чем больше ядер тем острее проблема блокировки и очевидней, что просто взять и разложить на много-много потоков уже хуже чем, например, 4 потока (на практике зависимость всего от одной разделяемой ячейки это идеальныый случай и, соотвественно, их - несколько, что сильно хуже и вообще - абзац..).
RE: Оптимизация архитектуры - Added by VaalKIA over 10 years ago
ak_multiclet wrote:
VaalKIA wrote:
А то как-то вы сразу со своими мьютексами встали на светлую сторону, а как же тёмная сторона силы? ;-)
Дык, я ж не спорю, что многопоточное/параллельное программирование -- вещь занятная и интересная.
Она не просто занятная, я так понимаю, многоядерность даже в самом названии Мульти у вас заложенна, так что я бы сказал - животрепещущая тема, которую надо активно прорабатывать уже сейчас и добавлять в проц нужные фишки.
Суть транзакции: есть переменная, значение которой будет использоваться прямо с самого начала функции, а в конце функции (это может быть цикл, и итерация скорее всего будет последняя, а может первая) - скорее всего модифицироваться (а может и нет, например умножаться на два). Если мы ставим блок на эту ячейку, а функция у нас очень времязатратная - секунды, то все несколько секунд всё что использует эту ячейку на чтение, будет висеть, потому что функция её может изменить. При этом даже в этой функции, она может остаться неизменной, а меленькие процедурки могут легко пользовать её на чтение и перед завершением своего функционала проверять не поменялась ли и не ждать пока завершится эта здоровущая дура. Понятно, что транзакции это не замена блокировкам, это просто необходимая вещь.
http://habrahabr.ru/post/221667/
http://blogs.msdn.com/b/ru-hpc/archive/2009/12/03/9931925.aspx
https://software.intel.com/ru-ru/blogs/2013/09/28/2?language=en
RE: Оптимизация архитектуры - Added by VaalKIA over 10 years ago
VaalKIA wrote:
Я уже написал, что для некоторых случаев вообще не нужны блокировки, поскольку порядок не важен, ну ведь полно же операций где от "перемены мест слагаемых сумма не изменяется", а важен только конечный результат. Соответственно, там нужна не блокировка, а буфер, тогда 4 ядра без всякого торможения одновременно "добавят" (поставят в очередь в буфер) в такой "аккумулятор" по числу и займутся своими делами, а его значение будет расти ещё 4 такта (ну это условно, там можно по разному сделать).
На самом деле, "расти 4 такта" это малоинтересно, поскольку тяжело отследить конечный результат.
В принципе, это всё та же запись в независыме ячейки независимыми потоками ака массив, только ввиду её элементарности, переведёная в железо с прошитой схемой параллельного суммирования и за счёт этого может быть быстрой и атомарной. Теперь поразмышляем. С одной стороны 1 такт гарантирует, что ничего быстрее нет и в середине операции никто к нам не лезет, с другой стороны: мы можем одновременно дать прочитать 1000 ядер значение этого регистра и так сделать схему, что бы одновременно 1000 ядер могли записать туда (буфер с параллельным вводом на 1000 слов это не проблема), а на следущем такте получить результат (что уже сложно схемотехнически но для сложения реализуемо, да пусть хотя бы будет тупо инкремент или декремент на 1цу). Но при этом, одновременное чтение и запись, это уже совсем другое дело, а в общем случае именно так и будет, какое-то из 1000 ядро всегда будет пытаться прочесть, какое-то записать. Получается что надо будет ещё и копию старого значения держать, которую отдавать только во время записи, соотвестветвенно её придётся чередовать, а для основной схемы тоже нужно старое значение, в общем всё это очень монструозно. А таких аккумуляторов, по сути чем больше тем лучше, так что физически получается утопия: их всегда будет не хватать для данных потоков и очень тяжело сделать в 1 такт. По сути такие аккумуляторы должны лежать в памяти, тогда не будет ограничений на количество, но и никаких 1 такта там вообще не светит никак. значит теряется атомарность появляются дедлоки.
Что можно сделать? Те же блокировки на время вычисления результата и чередовать приоритет для записи/чтения, что бы не получилось, что все пишут, хотя не могут прочесть (примитивное разруливание дедлоков). Получаются фиксированные задержки не более чем несколько тактов и массовая параллельная работа ядер с ячейками памяти на некоторых элементарных операциях. Стоит ли городить этот огород - вопрос..
Но вот список полезных инструкций составить можно. Понятно, что это должны быть атомарные инструкции, например, работа с уазателем - атомарная, поэтому в теории можно любой блок данных заменить мгновенно, просто переставив указатель на "заранее подготовленную позицию", но при этом надо убедиться, что никто этого не сделал до тебя и не пытается сделать одновременно с тобой. То есть, мы сохраняем старое значение указателя (ну это как в транзакции), а потом должны одним махом сравнить указатель с сохранённым значением, и если отличий нет, то его перезаписать. То есть комманда сравнивающая а и б и если они равны то а = ц, и всё это атомарно.
upd. Назвается это CAS (Compare And Swap) и несёт за собой проблему обозначаемую как ABA (не нашёл расшифровки, возможно следует трактовать как "проблема поочерёдного доступа", что как раз и иллюстрируется буквами). Суть проблемы в том, что указатель это всего лишь синоним данных и два одинаковых указателя не означают равность данных, поэтому, если не вешался лок на указатель, то данные по нему могли затереть, указатель обнулить, потом опять записать данные и поставить на них указатель, при этом получится так, что данные расположились по тому же месту, таким образом CAS у нас пройдёт, а вот данные будут не те, на которые мы расчитывали. Но полезность инструкции это не отменяет. Выход из положения каждому указателю (или данным) присваивается ещё и уникальный тег, который тоже должен сверяться, поэтому CAS делают разрядность побольше..
Общее название класса операций RMW (Read-modify-write):
compare-and-swap (CAS)
fetch-and-add (FAA)
Инкременирует ячейку и получает значение, которое было до инкремента.
test-and-set (TAS)
Чем отличается от FAA я не понял
Так же в противовес CAS есть
Load-Linked / Store-Conditional (RL/SC) которая не подверженна ABA проблемме.
Суть такая, проц отслеживает была ли реальная модификация ячейки по адресу, делается это с уловками с использованием кеша куда введён бит статуса, так что есть куда рости:
Современные архитектуры процессоров делятся на два больших лагеря – одни поддерживают в своей системе команд CAS-примитив, другие – пару LL/SC. CAS реализован в архитектурах x86, Intel Itanium, Sparc; впервые примитив появился в архитектуре IBM System 370. Пара LL/SC – это архитектуры PowerPC, MIPS, Alpha, ARM; впервые предложена DEC. Стоит отметить, что примитив LL/SC реализован в современных архитектурах не самым идеальным образом: например, нельзя делать вложенные вызовы LL/SC с разными адресами, возможны ложные сбросы флага linked (так называемый false sharing), нет примитива валидации флага linked внутри пары LL/SC.
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
Суть проблемы в том, что указатель это всего лишь синоним данных и два одинаковых указателя не означают равность данных, поэтому, если не вешался лок на указатель, то данные по нему могли затереть, указатель обнулить, потом опять записать данные и поставить на них указатель, при этом получится так, что данные расположились по тому же месту, таким образом CAS у нас пройдёт, а вот данные будут не те, на которые мы расчитывали. Но полезность инструкции это не отменяет.
Указатель -- это адрес данных и два одинаковых указателя ссылаются на одну и ту же ячейку памяти.
Если два одинаковых указателя ссылаются на одни и те же данные, то разве могут быть эти данные разные между собой ?
Инструкцию CAS я тоже затронул вверху, но привел пример её использования, как если бы она была не под указатели подогнана.
Вообще, если ей правильно пользоваться, то проблем не должно быть.
Например так:
...
auto next = new Node(value);
do {
prev = ptr;
next.prev = prev;
} while(!cas(&ptr, prev, next));
...
Тут если ptr == prev, то ptr станет равен next, функция вернёт true и цикл прервётся, т.к. инструкция атомарна, то для других потоков значение ptr изменится и оно не будет уже равно prev, функция вернёт false и цикл повторится.
RE: Оптимизация архитектуры - Added by VaalKIA over 10 years ago
Yaisis wrote:
Указатель -- это адрес данных и два одинаковых указателя ссылаются на одну и туже ячейку памяти.
Если два одинаковых указателя ссылаются на одни и те же данные, то разве могут быть эти данные разные между собой ?
Могут, потому что есть ещё такой фактор как время. И механизм я подробно описал. Опишу ещё раз. Односвязанный список, получаем копию указателя на элемент, потом нас прерывает другой поток, удаляет этот элемент, потом его прерывает другой поток - вставляет новый элемент, и память выделяемая в куче ложиться ровно в то же место, поэтому новый указатель будет указываь туда же, возвращаемся в первый поток и ему CAS разрешает перезапись, потому что указатели равны, а вот данные по ним уже не те.
RE: Оптимизация архитектуры - Added by Yaisis over 10 years ago
VaalKIA wrote:
Могут, потому что есть ещё такой фактор как время. И механизм я подробно описал. Опишу ещё раз. Односвязанный список, получаем копию указателя на элемент, потом нас прерывает другой поток, удаляет этот элемент, потом его прерывает другой поток - вставляет новый элемент, и память выделяемая в куче ложиться ровно в то же место, поэтому новый указатель будет указываь туда же, возвращаемся в первый поток и ему CAS разрешает перезапись, потому что указатели равны, а вот данные по ним уже не те.
Теперь я понял, что вы имели ввиду.
Если рассматривать в таком виде, то вы правы.
RE: Оптимизация архитектуры - Added by ak_multiclet over 10 years ago
Вот смотрите: сами по себе операции TAS и т.п. не используются для реализации "полезной нагрузки", их использует ядро при работе с примитивами синхронизации (вот такой вот я джедай, да), в которые, в свою очередь, "оборачиваются" уже более высокоуровневые вещи, типа манипуляций списками. Так вот, получается, что способ, которым ядро реализует самозащиту при работе с примитивами, пользовательскому коду не виден и не интересен. В одноядерных многопоточных системах оно просто блокирует планировщик. В многоядерных обычно используют атомарные инструкции. Но (насколько мне известно) они, чтобы быть атомарными, на время своей работы блокируют шины. Очевидно, нам такой способ совсем не подходит.
Можно зайти с другого конца, как это сделала Freescale: для хранения признаков использовать не простые ячейки памяти, а специальные аппаратные блоки. Каждая ячейка такого блока, условно говоря, представляет собой битовый флажок, который ещё и "видит", какое ядро пытается в него записать. Пока флажок сброшен, установить его может любое ядро. Как только он установлен, сбросить его может только то ядро, которое установило. Поскольку установка -- это одно обращение по шине, и оно по определению атомарно, то получаем функциональный аналог TAS, хорошо подходящий к нашей архитектуре.
RE: Оптимизация архитектуры - Added by VaalKIA over 10 years ago
ak_multiclet wrote:
Вот смотрите: сами по себе операции TAS и т.п.
Если придерживаться ключевых слов, то скорее операции RMW, а вот суть имено инструкций TAS я не понял, о чём уже писал.
Так вот, получается, что способ, которым ядро реализует самозащиту при работе с примитивами, пользовательскому коду не виден и не интересен.
Именно. Но тут скорее речь идёт о межядерном взаимодействии, ведь в мощных процах задействован кеш и прочие радости. Так что вполне допустим целый контроллер обеспечивающий правильный доступ ядер к данным с учётом инструкций. А по поводу "неинтересен", скажу такой факт CAS на некоторых архитектурах выполняется 200-400 тактов, на других 400-800 тактов (приблизительно и инфа старая), так что определённый интерес всё же есть - оно должно быстро работать, тогда пусть как хочет делается.
В одноядерных многопоточных системах оно просто блокирует планировщик. В многоядерных обычно используют атомарные инструкции. Но (насколько мне известно) они, чтобы быть атомарными, на время своей работы блокируют шины.
Не просто блокируют, ещё и выравнивание данных играет свою роль, поскольку прочесть слово, в два приёма - ломает всю картину.
Очевидно, нам такой способ совсем не подходит.
Мне не очевидно, но думаю что блокирование шины сразу всех 1000 ядер, мягко сказать провальное решение. Поэтому имеет смысл уточнить как происходит в современных интелах, тех же 16 ядерных.
Можно зайти с другого конца, как это сделала Freescale: для хранения признаков использовать не простые ячейки памяти, а специальные аппаратные блоки. Каждая ячейка такого блока, условно говоря, представляет собой битовый флажок, который ещё и "видит", какое ядро пытается в него записать. Пока флажок сброшен, установить его может любое ядро. Как только он установлен, сбросить его может только то ядро, которое установило. Поскольку установка -- это одно обращение по шине, и оно по определению атомарно, то получаем функциональный аналог TAS, хорошо подходящий к нашей архитектуре.
Это отсылка к кешу, соотвественно сразу же имеем проблемы с тем, что линейка кеша ограничена, а память, память она, сволочь - здоровая. Программист опять же, использовав в одном месте этот флаг, лишается возможность использовать его же на другом уровне (вложенные функции и процедуры), да и вообще, не должен ими слишком разбрасываться, потому что ресурс тут ограничен. Когда речь идёт о множестве потоков, то наши флаги могут очень быстро закончиться. И, возможно, в свете реализации MMU возникнут и другие проблемы. Но направление правильное, вместо того что бы как-то сразу поставить в блок обращение к 3 ячейкам памяти или вообще всё обращение к памяти, имеет смысл спокойненько поставить на контроль и потом разом узнать да или нет без всяких блокировок. Тем не менее тут ещё надо думать.
А что, если не отказываться от инструкций вроде CAS, но что бы они не блокировали всю память, а так же расставляли флаги но только для себя самой, а сама запись уже делается атомарно (тут тонкий момент, что для решения ABA проблемы надо работать с удвоенными данными: указатель + тег, но для начала хватит и просто CAS, для работы с данными размером в слово не по ссылке), но вместо блокировки шины контролируются эти флаги в момент записи. Получается, что нам нужно строго ограниченное количество флагов и нужны они на время выполнения одной инструкции, а сама инструкция получается транзакционной - выполняется пока, наконец, будет отстуствовать модификация данных во время её выполнения (надеюсь, что это промежуток всего в несколько тактов, но поскольку у нас ядер много, то как раз на эти такты и нужна гарантия). Получается инструкция TCAS, так же как TSQL :-)